 Creating and managing XML with open source software
Creating and managing XML with open source software
Abstract
This article reviews a number of open source XML applications and systems including editors, validators, native XML databases, and publishing systems; to describe how some of these tools have been combined by the author to create a specific system for a specific need. An overview of XML is provided, a number of open source XML applications/systems are reviewed, and a system created by the author using some of these tools is described. The open source tools for working with XML are maturing, and they provide the means for the library profession to easilyh publish library content on the Internet using open standards. XML provides an agreed upon way of turning data into information. The result is non-proprietary and application independent. Open source software operates under similar principles. An understanding and combination of these technologies can assist the library profession in meeting its goals in this era of globally networked computers and changing user expectations.
Introduction
In a sentence, the eXtensible Markup Language (XML) is an open standard facilitating a means to share data and information between computers and computer programs as unambiguously as possible. Once transmitted, it is up to the receiving computer program to interpret the data for some useful purpose thus turning the data into information. Sometimes the data will be rendered as HTML. Other times it might be used to update and/or query a database. Originally intended as a means for Web publishing, the advantages of XML have proven useful for things never intended to be rendered as Web pages.
It is helpful to compare XML to other written languages. Like others, XML has a certain syntax. One on hand, the syntax is very simple. You really only need to know six or seven rules in order to create structurally sound -- oftentimes called "well-formed" -- XML documents. On the other hand, since XML is also intended to be read by computers, the rules are very particular. If you make even the slightest syntactical error the whole thing is ruined. Here are the rules:
- XML documents always have one and only one root element
- Element names are case-sensitive
- Elements are always closed
- Elements must be correctly nested
- Elements' attributes must always be quoted
- There are only five entities defined by default (<, >, &, ", and ')
- When necessary, namespaces must be employed to eliminate vocabulary clashes.
Below is a "well-formed" XML document in the form of an XHTML file. It illustrates each of the seven rules outlined above and serves as an example only. Elaborating on each of the rules is beyond the scope of the article.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Hello, World!</title>
</head>
<body>
<h1 style='text-align: center'>Hello, World!</h1>
<p>It is nice to meet you.</p>
<p>Today we are going to re-enforce your knowledge of XML
and open source software. Remember,</p>
<ol>
<li>XML documents always have one and only one root
element</li>
<li>Element names are case-sensitive</li>
<li>Elements are always closed</li>
<li>Elements must be correctly nested</li>
<li>Elements' attributes must always be quoted</li>
<li>There are only five entities defined by default
(<, >, &, ", and ')</li>
<li>When necessary, namespaces must be employed to
eliminate vocabulary clashes.</li>
</ol>
</body>
</html>
Creating structurally sound -- syntactically correct -- XML is only part of the picture. In order to make sense, XML documents also need to be semantically correct. The elements of XML documents must be combined with each other and the data they encode in a manner making sense and is understood. There are many sets of semantic rules, and they can be encoded in at least a few different forms.
XML grew out of the SGML world, and consequently Document Type Definitions (DTDs) are a popular and well-supported way of encoding the semantic structure of XML documents. DTDs have their pluses and minuses. On the plus side they are common and rather simple to understand. On the minus side DTDs are not written as XML documents and consequently require a different sets of tools to process. Ironic. Additionally, DTDs are not very good at data typing. There are no ways to differentiate between numeric data and character data. Furthermore, there is no way to dictate the shape of these data as dates, ranges, embodying specific patterns, etc. In reaction to these limitations a few other methods for describing the semantic structure of XML have been introduced. The most notable of these are W3C schema files and RelaxNG schema files. It is suffice to say there are advantages and disadvantages of both, but they are both based on XML and resolve the deficiencies of DTDs.
That being said, below is very simple XML file that includes a DTD. By reading the file it should not be too difficult for you to discern what it describes. Moreover, since the file is grammatically correct in terms of XML -- it is well-formed as well as validates against a DTD or schema -- it should not be too difficult for a computer to read and process as well:
<!DOCTYPE pets [
<!ELEMENT pets (pet+)>
<!ELEMENT pet (name, age, type, color)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT type (#PCDATA)>
<!ELEMENT color (#PCDATA)>
]>
<pets>
<pet>
<name>Tilly</name>
<age>14</age>
<type>cat</type>
<color>silver</color>
</pet>
<pet>
<name>Loosey</name>
<age>1</age>
<type>cat</type>
<color>brown</color>
</pet>
<pet>
<name>Stop</name>
<age>5</age>
<type>pig</type>
<color>brown</color>
</pet>
</pets>
The final part of this introduction is rendering and transformation. While XML documents are readable by humans, they are not necessarily reader friendly, especially considering certain devices and outputs. Furthermore, it may be desirable to analyze, summarize, rearrange, and extract parts of an XML file. This is where Cascading Style Sheets (CSS) and Extensible Stylesheet Language (XSL) come into play.
The strengths of CSS lie in its presentation abilities. It excels at layout, typography, and color. By creating styling characteristics (called "declarations") with XML elements and combining them with XML files, the results are presentations of the original XML document that are easier to read. These presentations can be designed for various Web browsers, printing, or even devices intended for speaking. For example, CSS provides the means to align text, insert text in boxes, dictate the spacing between paragraphs, specify the use of various fonts, etc.
Through a combination of supplementary technologies, most notably XSL Transformations (XSLT), it is possible to implement all of the functionality of CSS plus manipulate XML, sort XML, perform mathematical and string functions against XML, and thus "transform" XML into other (unicode/"plain text") files. This means it is possible to take one XML file as input and through XSLT convert the file into a Formatting Objects (FO) document designed for printing, an HTML document designed for display in a browser, a comma-separated file destined for a spreadsheet application, an SQL file for importing into or querying a relational database, etc. The cost of all this extra functionality is a greater degree of complexity. Implementing XSL and its supplementary technologies is akin to programming. As an example, below is a simple XSLT file creating a rudimentary HTML stream summarizing the contents of the pets XML file, above:
<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform'
version='1.0'>
<xsl:template match='pets'>
<html>
<head>
<title>Pets</title>
</head>
<body>
<h1>Pets</h1>
<ul>
<li>
Total number of pets:
<xsl:value-of select='count(pet)' />
</li>
<li>
Average age of pets:
<xsl:value-of select='sum(pet/age) div count(pet)' />
</li>
</ul>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Equipped with a text editor, a relatively modern Web browser (one that knows how to do standardized CSS and XSLT), and the knowledge outlined above it is entirely possible to implement a myriad of XML-based library collections and services. For example, it would be possible to mark up sets public domain documents using TEI (Text Encoding Initiative) and make them available as browser-friendly HTML documents on the Web. The sets of TEI documents could be encoded as finding-aids using EAD (Encoded Archival Description) in order to guide users on the collection's use. The TEI or EAD files could be transformed into SQL (Structured Query Language) or MARCXML files and then imported into databases for maintenance and/or searching.
Open Source Tools For Processing XML
While using just a text editor, a Web browser, and your knowledge is a great way to learn about XML, it is not very scalable. Using just these tools it would be difficult to create collections and services of any significant size. Developers understand this, and that is why a bevy to applications have been created to facilitate the creation and maintenance of XML data/information on a large scale. Some of these tools are described in the following sections.
Parsers
Of all the things in the XML toolbox, I find XML parsers (validators) to be the most useful. These tools check your documents for well-formedness and make sure they validate against a DTD or schema. They are sort of like the spell checkers and grammar checkers of word processing applications, and, fortunately, they are much more accurate because the rules of XML are much more simplistic when compared to the "rules" of purely human written or spoken languages.
Xmllint
Xmllint is an XML parser built from a C library called libxml2 and used as a part of the Linux Gnome project. [1] (Gnome is a user interface for Linux.) Because libxml2 is written in C, and because great care has been taken to implement no operating specific features, it is known to work on just about any computer. You can acquire libxml2 in source form or pre-compiled binaries. Xmllint is run from the command line. Assuming a DTD is specified in the root of your XML document, a command like the following will validate your XML: xmllint --valid pets.xml. If the XML is well-formed and validates, then the XML will be returned in a parsed form. If the XML does not validate, then the XML will be returned in the parsed form and a message will describe what the parser found and what it expected. Sometimes these messages can be cryptic, but all the validators return rather cryptic results. Libxml2 (and consequently xmllint) will also validate XML against external DTDS and XML schemas (both W3C and RelaxNG schema files). If your XML takes advantage of XInclude functionality, then xmllint will process these as well. Finally, a number of other libraries/modules have been written against the libxml2 library allowing people to use libxml2 functionality in Perl, Python, or PHP scripts. XML::LibXML2 is the Perl module implementing just this sort of thing. Of all the tools listed in this article, xmllint is the tool providing the biggest bang for its buck.
MSV
While not necessarily open source, but freely available for download and complete with source code, Sun Microsystems' Multi-Schema XML Validator (MSV) is a decent XML validator. [2] Written in Java, this tool will validate against a number of grammars: Relax NG, TREX, and XML DTD's. Once you've gotten Java installed and your CLASSPATH environment variable set up, you can type java -jar msv.jar pets.dtd pets.xml to validate a file named pets.xml. Simple and straight-forward. Since it is written in Java it should run on any number of operating systems. MSV does not seem to have been updated for a couple of years.
xerces-c
Like libxml2, xerces-c is a C library for parsing XML. [3] It is supported by the Apache Foundation, and provides the means for creating binaries for specific purposes as well as creating hooks into interpreted languages such as Perl. XML::Xerces is an example. The process of building the libraries is non-standard but functional. The same is true for building the sample applications. One of the more useful is StdInParse. By piping to StdInParse an XML file, this application will read the data and report errors it finds. An example invocation includes ./StdInParse < ./pets.xml. With a number of optional flags it will check namespaces, schemas, and schema constraint. Even considering these features, the xmllint application is still more funcational. At the same time, it should be kept in mind that StdInParse is an example application. Xerces-c is really a library for the C programmer, not a set of binaries. XML::Xerces, a Perl module, is built against this library. Implementers need to know how to read the C instructions in order to make the most of the module.
Editors
There are quite a number of XML editors but most of them are not open source. I don't know why. Maybe it is because a "real" XML editor has to not only has to provide the ability to do basic text editing tasks but it also needs integrate itself with XML, and if this is the case, then you might as well piece together the tools you need/desire instead of implementing a one size fits all solution. Furthermore, XML is not necessarily intended for display, so it is not going to work well in a WYSIWYG environment.
jEdit
JEdit is a pretty nifty XML editor. Written in Java, it should run on just about any computer with a Java Virtual Machine installed. [4] The interface is a bit funky, but you can't hold that against it since it is trying to play nice with three different user-interfaces: Windows, Linux, and Macintosh.
Given a DTD or schema, jEdit is smart. It will examine the given XML grammer, and as you start typing it will create a list of possible elements available at that location in your document. If your element includes attributes, it will create a list of those as well. You can then select the elments and attributes in order to reduce the amount of typing you need to do as well as the number of possible mistakes you can make. If you import a file for editing and/or when you save a file you are editing, jEdit will validate your document and report any errors you have created. Very handy, and gets you away from using a parser like xmllint or Saxon (described below). JEdit also supports XSLT. Given an XSLT stylesheet jEdit will transform your document, again, without using xsltproc or Saxon.
JEdit is really a text editor, not only an XML editor. Therefore it contains functions for creating markers in your text, wrapping text, extensive find/replace functions, macros, word counting, etc. It is able to provide the XML functions through sets of "plug-ins" and there are dozens of other plug-ins to choose from.
JEdit is an example of what Java was originally designed to do. Write once. Use many. Editing XML with jEdit can be a joy if you are willing to use an interface that you may not be accustomed.
emacs
As you may or may not know, emacs is more like a computing environment as opposed to just an editor. If you use emacs regularly, then you probably think it is great. On the other hand, most people find the innumerable key-stroke combinations, modes, and buffers very difficult to learn and remember. For those who like emacs and want to edit XML, first there is psgml. [5] Psgml will read DTDs and allow you to edit XML files against them. Like JEdit, it includes options for collapsing and expanding elements, selecting elements for insertion, and overall validation. Most, if not all, of the operations psgml can perform are located in the menus. This make things easier to remember, but also makes the interface more cumbersome.
Nxml is another XML editing mode for emacs. [6] By default it knows how to validate against DocBook, RDF, XHTML, XSLT DTDs/schemas. You can also specify a RELAX NG schema of your own design. It too will list elements that are valid in specific parts of your document. It color codes your XML, unlike psgml. Nxml can be configured to constantly validate your documents. When errors occur you can place your cursor over the highlighted error and nxml will give you hints on how to fix them. Nice.
If you specifically need/want to edit TEI files, and you are an emacs fan, then consider TEI Emacs. [7] Put together by the folks of the TEI Consortium, this (RPM and/or Debian) package will install psgml, nxml, as well as the TEI schema and some XSLT stylesheets.
Databases
Because of the highly structured nature of XML files, the use of XML as a technique for storing data and information is often explored. These explorations eventually become "native" XML databases -- database applications storing XML files as whole chunks and providing database-like functions against them. These functions include global find/replace routines, reporting, importing, and exporting. These are interesting explorations, but they do not seem to have caught on in a really big way with the computing community.
eXist
EXist is a native XML database written as a set of Java archive (.jar) files. [8] These files are combined together in a number of ways to create the database application. For example, there is a rudimentary Web interface, but there is a nice windowed/desktop interface too. This means you can install eXist as a Java servlette. You can start the client a second way, and access it through a Web interface on your own host. Or you can use the fire up the windowed client application.
To use eXist you create "databases" in the form of directories on your file system. You then import XML files, of any type, into the directory. Once there, you are expected to write and run XQuery scripts againt the database. (XQuery is, more or less, an enhancement of XPath with the addition of conditional statement such as if-then constructions. In this regard, it is similar to XSLT, but XQuery scripts are not XML files.) After you find things in your database (which can be entire XML files, text within elements, or the returned results of functions) you have the opportunity to export the data or transform it into something else.
Like a lot of windowed Java things on my machine, eXist was not very snappy. It requires you to have a good understanding of XPath and/or XQuery in order to use it effectively. Unless you don't have Java installed on your computer, there is no reason why it shouldn't run on your machine and because of its graphical nature, it would be an excellent tool for learning XPath and XQuery.
XSLT processors
I find XSLT processors the second most useful tool in the XML developers toolbox. As mentioned in the introduction, these tools convert ("transform") XML files into other plain text files whether they be other XML files, delimited files, or text files with no apparent structure. Creating XSLT files is akin to writing computer programs in the form of XML.
Xsltproc
Xsltproc is an XSLT processor based on the libxml2 C library mentioned above. [9] This processor implements all of the XLST standard funcations as well as a few extensions such as the document and include functions. To use xsltproc you feed it one or more options, an XSLT stylesheet, and your source XML files something like this: xsltproc pets.xsl pets.xml > pets.html. Such a command will combine the pets.xsl and pets.xml files and save the resulting transformation as pets.html. Using the --stringparam option you can define the values of XSLT parameters and simulate configurations for your stylesheet. Since xsltproc is an implementation created against a library, other languages can take advantage of this library and include its functionality in them. XML::LibXSLT is a Perl module doing just that and allows the programmer to include XSLT transformation functions in her applications. As an example, the following snippet of code combines an XML file with an XSLT stylesheet, stores the result to a variable called $results, and prints it. The process is confusing at first, but very handy once understood:
# transform an XML document
my $parser = XML::LibXML->new;
my $xslt = XML::LibXSLT->new;
my $source = $parser->parse_file('twain.xml');
my $style = $parser->parse_file('tei2html.xsl');
my $stylesheet = $xslt->parse_stylesheet($style);
my $results = $stylesheet->transform($source);
print $stylesheet->output_string($results);
xalan
Like xsltproc, xalan is a set of C libraries (and subsequent command-line application) providing the means for the programmer to include XSLT functionality into their program. [10] Like xsltproc, it requires a previously installed XML parser, in this case xerces-c. Building the libraries is not difficult, just following the instructions, and be sure to make the sample applications in order to use the command-line applications. Transforming a document was as simple as XalanTransform pets.xml pets.xsl pets.html. The transformation is rudimentary, but only because it is a sample application. Unless you are a C programer, for day-to-day transformations, you will probably want to use Saxon or xsltproc.
The xalan distribution also comes with an Apache module allowing you to transform XML documents with XSLT on the fly. The functionality is much like AxKit, described below. Compile the module. Install it and the necessary libraries. Configure Apache. Restart Apache. Write XML and XSLT files saving them in the configured directory and when files are requested from the configured directory they will be created by transforming the XML with the XSLT.
Xalan is a member of the large Apache Foundation suite of software. If you ever have the need for open source software, and the Apache Foundation has an application fulfilling your need, then consider using that application. The Foundation's software has a good reputation.
Saxon
Saxon is a Java-based XSLT processor written and maintained by the primary editor of the XSLT specification, Michael Kay. [11] Saxon comes in two flavors. One, Saxon-A, is a commercial product and supports XML schema. The other, Saxon-B, is open source and does not support XML schema. Both support the latest version of the XSLT standard (version 2.0), XQuery 1.0 and XPath 2.0. Saxon-A and B seem to be the first to implement these standards.
Like most of the tools here, Saxon is intended to be incorporated into other applications, but it can be run from the command line as well. A command like this transforms an XML document with an XSLT stylesheet to produce and HTML file: java -jar saxon8.jar -t twain.xml tei2html.xsl > twain.html. Works for me.
Saxon supports a number of extensions -- functions not specified in the various standards. From the Saxon documentation, some of the more interesting extensions are:
- decimal-divide() - performs decimal division with user-specified precision
- format-dateTime() - formats a date, time, or dateTime value
- max() - finds the maximum value of a set of nodes
- parse() - parses an XML document supplied as a string
- sum() - sums the result of computing an expression for every node in a sequence
- try() - allows recovery from dynamic errors
Implementing these extension in your applications may be helpful, but they will also limit the portability of your system if you need to migrate later.
Complete with plenty of source code and complete documentation, Saxon is well-worth your time if your programming language of choice is Java.
Publishers
There exist entire systems for publishing XML. These systems take raw XML as input, combine it with XSL on-the-fly, and deliver it to the user. Cocoon is one such system. [12] If you are into TEI then TEI Publisher is another [13]. I prefer AxKit.
AxKit
AxKit is a mod_perl module allowing the XML developer to incorporate XSLT processing into the Apache HTTP server. [14] It provides the means of transforming XML upon request and delivering it to HTTP user-agents in formats most appropriate for the end-user. In other words, when a user-agent requests an XML file, your Web server can be configured to transform the XML with an XSLT stylesheet (as well as any input parameters) and output text in the desired format or structure. No need to transform the XML ahead of time and save many documents. Thus, AxKit implements the epitome of the "create once, use many" philosophy.
Installing all of the underlying infrastructure required by AxKit is not trivial. First you need mod_perl and installing it along side something like PHP can be confusing. AxKit then relies on the libxml2 and libxslt libraries and consequently these must be installed too. Finally, your Apache (HTTP) server needs to be configured in order to know when to take advantage of AxKit functionality. If you can configure all these technologies, then you can configure just about anything.
As an exercise, I implemented a Webbed version of my water collection using MySQL, PHP, and AxKit. [15] To implement this collection I first created a relational database designed to maintain an "authority list" of water collectors as well as information about specific waters. The database includes a BLOB field destined to contain a photograph of each bottled water. I wrote a set of PHP scripts allowing me to use an HTML form-based interface to do database I/O. In addition I wrote another PHP script creating reports against the database. There are really only two types of reports. One report exports the contents of the BLOB fields and saves the results as JPEG images on the file system. The other report is an XML file of my own design. Each record in the XML file represent one water and it includes date, collector, name, and description of the water. I then wrote an XSLT stylesheet designed to take specific types of input like collector name IDs or water IDs. Finally, I configured my HTTP server to launch AxKit when user-agents access the water collection. The result is a set of dynamically created HTML pages allowing users to browse my water collection by creator or water name. Something very similar could be done for sets of text files (prose or poetry) or even sets of metadata such as MARCXML or MODS files.
AxKit is an underused XML implementation, probably because it is hard to install.
Building A System - My TEI Publisher
I make no bones about it. I'm not a great writer. On the other hand, over the years, I have written more stuff than the average person. Furthermore, I certainly don't mind sharing what I write whether it be prose, the handout of a presentation, or the code to a software program. I've been practicing "green" open access and open source software long before the phrases were coined. As a librarian, it is important for me to publish my things in standard formats complete with rich meta data. Additionally, I desire to create collections of documents that are easily readable, searchable, and browsable via the Web or print. In order to accomplish these goals I decided to write for myself a rudimentary TEI publishing system, and this section describes that system. [16]
Ironically, this isn't my first foray into this arena. When the Web was still brand new (as if it still isn't), I wrote a simple HTML editor using Hypercard called SHE (Simple HTML Editor). Later, I wrote a database program with a PHP front-end . Both systems created poorly formatted HTML, and both of those systems worked for a while. I suspect my current implementation will not stand the test of time either, but the documents it creates are not only well-structured but validate against TEI and XHTML DTD's. The system also supports robust searching capabilities and dissemination of content via OAI.
MySQL database
The heart of the system is a MySQL database, and the code I've written simply does I/O against this database. The database's structure is simplistic with tables to hold authors, subjects, templates, stylesheets, and articles. There are many-to-many relationships between authors and articles as well as subjects and articles. There are simple one-to-many relationships between templates and articles as well as stylesheets to articles. The scheme also includes a rudimentary sequence table in order to not mandate the use of MySQL's auto_increment feature.
Musings.pm
While the database is the heart of the system, a set of object oriented Perl modules reduces the need to know any SQL. The Perl modules make life much easier, and I call them Musings.pm. Each module in the set corresponds to a table in the database, and each module simply sets and gets values, saves and deletes records, and supports global find routines. After all that is all you can do with databases: 1) create records, 2) find records, 3) edit records, and 4) delete records.
Administrative interface
Once the modules were written I was able to write an administrative interface in the form of a set of CGI scripts. Like the modules, there is one CGI script for each of the tables in the database. For example, the authors.cgi script allows me to add, find, edit, and delete author information -- an authority file in library parlance. The subjects.cgi script allows me to manage a set of controlled vocabulary (subject) terms used to classify my articles. The templates.cgi file facilitates the maintenance of TEI skeletons. These skeletons contain tokens like ##AUTHOR## and ##TITLE##, and they are intended to be replaced by real values found in the other tables in order to create valid TEI output.
The articles.cgi script is the most complex. It allows me to enter things like title, date created, abstract, and changes information. It also allows me to select via pop-up menus subject terms, authors, templates, and stylesheets to associate with the article.
Once all the necessary information is entered, I use article.cgi's "build" function to amalgamate the meta data and content with the associated template. The resulting XML is then saved locally. I then use the script's "transform" function to change the saved XML into XHTML through the use of an XSLT stylesheet. (The stylesheet, like the template, is managed through a CGI script.) The XHTML files are complete with Dublin Core meta tags. Throughout this entire process I am careful to validate the created documents for not only well-formedness but validity as well.
It is important to note the administrative interface is more of a publishing system and is in no way an editor. Each of the parts of the system (authors, subjects, templates, stylesheets, articles) are expected to include XML mark-up. It is up to me to mark-up the content before it gets put into the system. To accomplish this, I use a text editor (BBEdit) on my desktop machine, and BBEdit allows me to create a "glossary" or set of macros to mark-up the documents easily. The administrative interface simply glues the parts of the system together and saves the result accordingly.
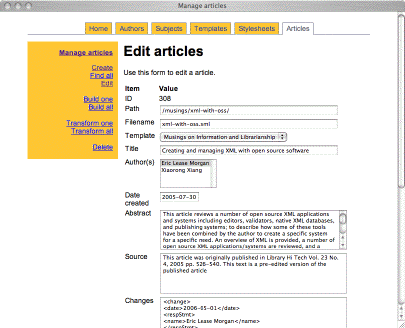
Admin interface (editing a file) |
{kind=link}
As the size of any collection grows so does the need for search functionality, but free text searching against relational databases is as pain. Such functionality is not really supported by relational database applications. Creating an index against the content of the database (or a set of files) makes searching much easier. Consequently, I provide search functionality through an indexer.
Currently, my favorite indexer is swish-e. [17] It supports all features librarians love: phrase searching, Boolean logic, right-hand truncation, nested queries, field searching, and sorting. Swish-e excels at indexing HTML files and/or XML files. During the indexing process you can specify what HTML elements are to become possibilities for field searches. I specify the Dublin Core meta tags.
Thus, after I create my XHTML documents, I index the entire lot using swish-e.
User interface
I have now created a set of stand-alone, well-formed, valid TEI and indexed XHTML documents. What is then needed is a user-interface. Because all of the documents have been described with a set of controlled vocabulary terms, I can create a list of these terms and then list the articles associated with each term -- a subject index. Since each article is associated with a date, I can list my articles in reverse chronological order. Since each article has a title, I can list them by alphabetically -- a title index. Since the entire corpus is indexed, I can provide a search interface to the content.
To make this happen I wrote one more CGI script, the system's home page . This page includes an introduction to the collection, a search box, and a list of three links to title, date, and subject indexes. These indexes are created dynamically taking advantage of Musings.pm. If I got fancy, I could count the number of times individual articles where read and provide a list of articles ranked by popularity. Similarly, I could watch for types of searches sent to the system and create lists of "hot topics" as well.
Now here's a tricky thing. I know the subject terms of each article. I know the content has been indexed with swish-e. Therefore I know the exact swish-e query that can be used to find these subject terms in the corpus of materials. Consequently, in the footer of each of my documents, I have listed each of the article's subject terms and marked them up with swish-e queries. This allows me to "find more articles like this one."
As you may or may not know, an index is simply a list of words associated with pointers to documents. Swish-e provides a means of dumping all the words to standard output. By exporting the words and feeding them to a dictionary program, I can create a spell-checker. I use Aspell for this purpose. [18] Consequently, when searches fail to produce results, my user interface can examine the query, try to fix mis-spellings, reformat the query, and return it to the end-user thus providing a "did you mean" service a la Google.
Lastly, I was careful to include the use of cascading stylesheet technology into the XHTML files. Specifically, I introduced a navigation system as well as a stylesheet for printed media. This provides the means of excluding the navigation system from the printed output as well as removing the other Web-specific text decorations. I think my documents print pretty.
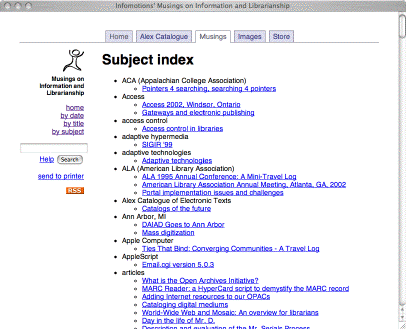
User interface (subject listing) |
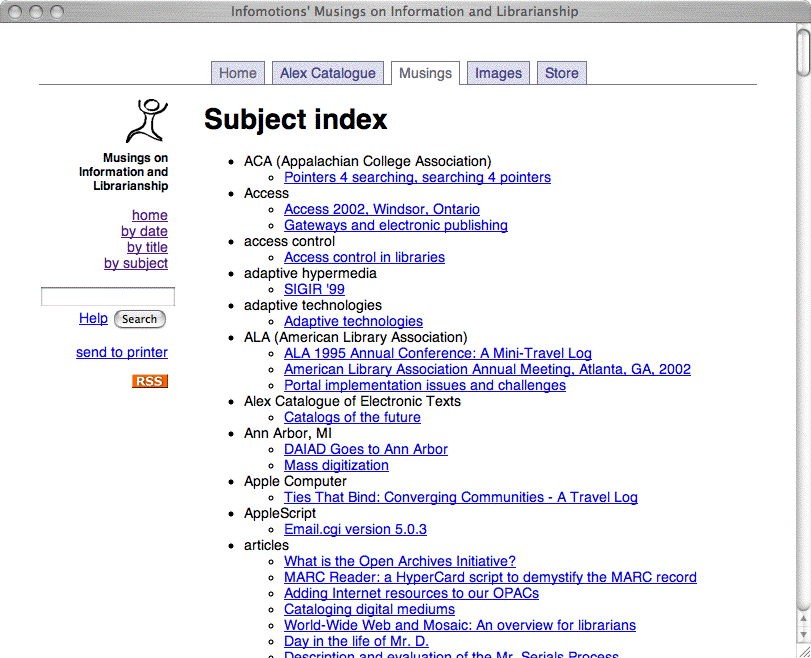{kind=link}
The documents of my collection are mere reports written against the underlying database. There is no reason other reports can not be written as well, and one of those report types are OAI streams. Again, using the Musings.pm module, I was able to write a very short program that dumps all of my articles to sets of tiny OAI files. These files are saved to the file system and served to OAI harvesters through a simple, Perl-based OAI server called OAI XMLFile. [19]
Conclusion
Creating the infrastructure to publish my documents was rather time consuming, but once this infrastructure was in place, it made it very easy publish a great number of documents consistently and accurately. Here is the process I use to publish things:
- Have an idea.
- Write it down.
- Mark it up in TEI.
- Assign subject terms
- Make sure the terms are in the database.
- Add the TEI to the database; do data entry.
- Build the TEI file.
- Check it for validity.
- Transform it into XHTML.
- Check it for validity.
- Index the entire corpus.
- Create OAI reports.
- Go to Step #1.
Given this system, I am able to spend most of my time articulating my ideas and writing them down. Steps #3 through #12 require only about thirty minutes.
Sometimes I feel like Ben Franklin. He was a writer (a much better writer than myself). He owned his own printing press. (In fact he owned many of them across the colonies.) He also designed his own typeface. Not only that, he was Postmaster for a while. In short, he had control of the entire distribution process. With the advent of the Web, much of that same distribution process is available to people and institutions like myself. All that needs to be done is design systems that fit one's needs and implement them. Such things exemplify enormous opportunities for cultural heritage institution such as libraries, museums, and archives -- as well as individuals.
Notes
- http://xmlsoft.org/
- http://www.sun.com/software/xml/developers/multischema/
- http://xml.apache.org/xerces-c/
- http://www.jedit.org/
- http://sourceforge.net/projects/psgml/
- http://www.thaiopensource.com/nxml-mode/
- http://www.tei-c.org/Software/tei-emacs/
- http://exist.sourceforge.net/
- http://xmlsoft.org/XSLT/
- http://xml.apache.org/xalan-c/
- http://saxon.sourceforge.net/
- http://cocoon.apache.org/
- http://teipublisher.sourceforge.net/docs/
- http://www.axkit.org/
- Yes, I collect water. There are about 200 items in the collection and it represents natural bodies of water from all over the world. The Webbed version of the collection only includes a sample of the entire thing, but my offices are littered with bottles of water from strange and wonderful places. See: http://infomotions.com/water/.
- http://infomotions.com/musings/tei-publisher/
- http://www.swish-e.org/
- http://aspell.sourceforge.net/
- http://www.dlib.vt.edu/projects/OAI/software/xmlfile/xmlfile.html
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This article was originally published in Library Hi Tech Vol. 23 No. 4, 2005 pp. 526-540. This text is a pre-edited version of the published article
Date created: 2005-07-30
Date updated: 2006-05-01
Subject(s): articles; TEI (Text Encoding Initiative); XML (eXtensible Mark-up Language); open source software;
URL: http://infomotions.com/musings/xml-with-oss/