 Web-scale discovery indexes and "next generation" library catalogs
Web-scale discovery indexes and "next generation" library catalogs
This essay outlines a definition of "Web-scale" discovery indexes and describes how they are interrelated with the ideas of "next generation" library catalogs. It was originally created for webcast called "Returning the Researcher to the Library: Defining Web-Scale Discovery" sponsored by Serials Solutions and Library Journal. A subset of these remarks are also available as a set of Powerpoint slides.
The problems to be solved
What is the purpose of our libraries? Why do they exist? What is/are the problem(s) librarianship is trying to solve? The answers to such questions are not definitive, especially when applied to individual libraries, but taken en masse the answers probably surround sets of services provided to a hosting community. If you work in a school library, then your community includes the people in the school. If you work in an academic library, then the community is a college or university. If you work in a public library, then the community is your local municipality. And even though each library supports a different community, there are sets of common functions which all libraries facilitate including collection, preservation, organization, and dissemination. We apply these processes to data, information, and knowledge in a variety of forms and formats. Libraries collect, preserve, organize, and disseminate content for the purposes of making the work of their respective communities easier whether that work be learning, teaching, or research. To one degree or another, just about every library does this sort of work, and just about everything us librarians do can be associated with one of these processes.

special library |

public library |

academic library |
What versus how; two case studies
Collection, preservation, organization, and dissemination are "whats" of librarianship. They are not "hows". They represent what we are suppose to be doing but not how they are suppose to be done. They are strategic objectives -- never completely accomplished but acted upon to fulfill our set of ultimate goals. They do not describe the specific tasks of our work. That is left up the the how of our work, our day-to-day operations, the specific workflows within each of our libraries. The whats of librarianship change very slowly. They ought to be as timeless as the missions of our hosting institutions. To foster learning. To support an informed public. To discover new and better ways to improve the human condition. Etc.

collections |

organization |

preservation |

public service |
The hows of librarianship, on the other hand, change at a much faster pace. These changes are usually driven by technology. Consider the venerable library catalog and its age. A conservative estimation will be a couple hundred years. A liberal estimation will date back two thousand years. Consider how librarians have maintained those catalogs. Initially they were kept in the memory of the librarian. Sometime after that they were written on scrolls. With the invention of the codex, library catalogs were eventually kept in book form. With the advent of the printing press, the catalogs were mass-produced, sometimes. The introduction of cards made catalogs easier to maintain, even though they were written by hand. The introduction of typewriters made it easier to get more on the cards and easier to standardize. With the introduction of copy machines skeleton cards could be created and added entries could be... added. With the introduction of computers electronic records could be created making the distribution of "cards" easier. Once the cataloging data is in electronic form, why use cards at all; make the data searchable and the "OPAC" is born. Changes in technology drove changes in catalogs.

library catalogs |

journal indexes |
The development of journal article indexes is similar. Journals appear as a form of literature during the Scientific Revolution. Societies publish their journals to communicate their findings. While I have never seen such a card, to make articles findable catalog cards were written describing the existence of specific articles. This proves to be very labor intensive and as a result a man name Poole comes along and says, "I'll do that work for you. I'll create a list of journal articles on a regular basis and you can subscribe to my list." Poole's Index to Periodical Literature was born. The technology of journal literature does not change very much until the advent of the MEDLINE and ERIC databases. DIALOG and BRS come along hosting dozens and dozens of online databases. CDROMs are invented and the end-user searching of electronic journal databases becomes the norm. The Internet happens, and the content is no longer distributed on CDs but centralized, and regularly includes the full text of the articles, not just its metadata. Just like library catalogs, the goal remained the same -- to provide access to the literature -- but changes in how the task was accomplished was driven by changes in technology.
Indexes, not databases
With the advent of freely available, industrial strength indexers -- not databases -- we are beginning to see another evolutionary step in the development of the library catalog and the way libraries provide access to journal literature. Summon is an example of this evolutionary progression, but it is not the only nor is it the first of its kind.
Remember, our ultimate goal has been to provide information services to our clientele. This is done through a number of strategic objectives: collection, preservation, organization, and dissemination. For decades, if not hundreds of years, our day-to-day tasks surrounded the maintenance and use of catalogs and indexes -- silos of content, and the hows of our work. Given these assumptions, the problem to solve may be stated as, "How do I exploit the current (technological, physical, political, fiscal, social, etc.) environment to achieve my goals?"
In the present day, when most newly created content is "born digital", it is possible to create full text journal article indexes with off-the-shelf indexers and thus make the content searchable. Lucene -- an open source indexer produced by the same foundation who produces the Apache HTTP server -- is the current gold standard. Others preceded it. Index Data's Zebra indexer and Z39.50 server combination is a very good example. It has been integrated into many of our current library systems. Swish-e is a another example and still quite practical today. Harvest was a third. Probably the first widely adopted and free indexer/search engine was WAIS from Thinking Machines. Through the use of freely available indexing technologies is it possible to create our own indexes instead of relying on publishers to do it for us, especially if the content to be indexed is open access -- such as the metadata describing our library holdings, items listed in the Directory of Open Access Journals, the digitized books from the Internet Archive, or just about any other content available in our communities or on the Web.
Computer-generated indexes function very much like back-of-the-book indexes but "smarter". Given sets of data, they extract all the words from a document and associate each word with locations. These locations include document identifiers and position attributes. The search engine -- the other half of the indexer -- takes unstructured input (words), looks them up in an ordered list of indexed terms, and returns document identifiers. Field specification is optional, not necessary. No need to know the structure of the underlying data. Boolean logic is supported by creating sets of document identifiers from multiple inputs and determining which identifiers are in all sets (Boolean "or"), one but not another set (Boolean "not"), or a combination of sets (Boolean "and"). Phrase searches are supported by subtracting the positions of search terms in documents. Terms whose positions are different by 1 denote phrases and therefore matches. Most importantly, relevancy ranking algorithms -- methods usually determining which documents contain relatively more occurrences of search terms -- are possible with computer-generated indexes. All of this is the product of the information retrieval community and is best represented by Google. In short, computer-generated indexes have not only matured, but they have become cheap enough to be used and exploited by any person or institution with a modicum of computer programing expertise.
Considering the current environment, indexing is a significant game changer -- it radically alters the how we can do our work.
The next steps; a recipe
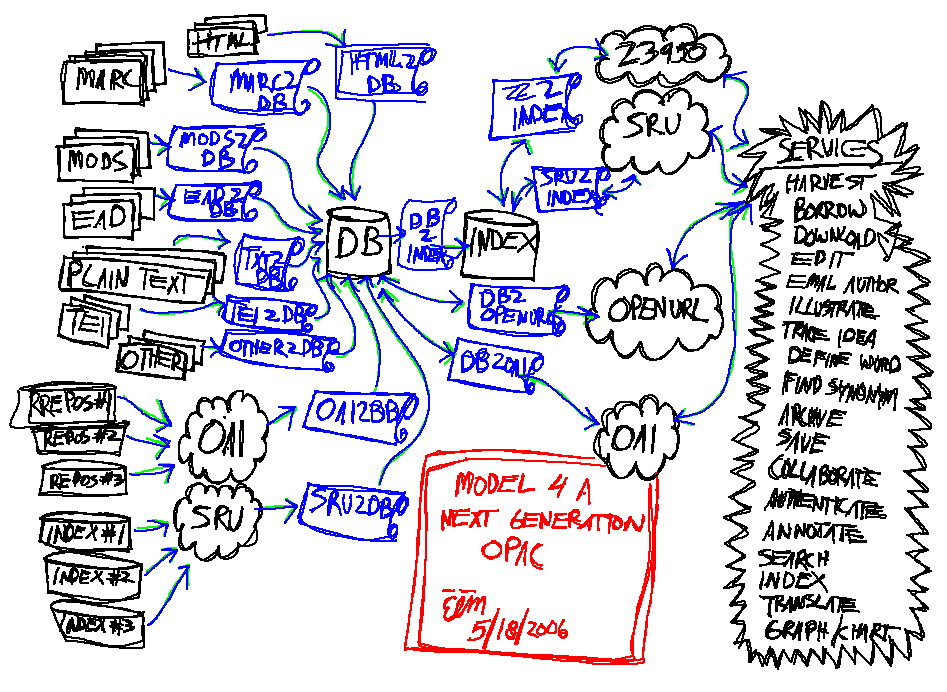
"next generation" library catalog |
{kind=link}
What process can be used to take advantage of this environment, to exploit it for our own purposes, and to implement new services? What are the next steps? The creation and maintenance of a combined book/journal article index is an excellent example. To the best of our ability, but all of our content into a single, seamless pile. Consider the following "recipe":
- Allocate resources - These resources include people with a variety of experience in collections, preservation, cataloging, public service, and computer technology. The resources include time, say, one year. Finally, the people will need a computer to manifest the fruits of their labors. Considering today's prices, something costing about $5,000 is enough to get started.
- Charge the group - Give direction to the people doing the work. Charge them with creating a one-box, one-button search interface to your combined book holdings, institutional repository materials, and some open access content in the form of scholarly journal articles or electronic texts
- Wait three months - During this time allow the people do to fulfill their charge. During this time the people will:
- Dump MARC records from your integrated library system
- Export metadata from your institutional repository
- Harvest and/or mirror open access article/etext content and metadata
- Feed all of this content to an indexer
- Design a simple user interface to search the index
- Ask for an update - After three months, ask for a progress report.
- Go to Step #3 four times - In other words, after twelve months the first iteration of the recipe should be complete.
- Evaluate - Ask yourself, to what degree was the project a success? Using the process your team implemented were they able to efficiently collect, preserve, organize, and disseminate data, information, and knowledge to your hosting institution? Was the investment in time, energy, and money worth the expense? Were you better able to take advantage of the technological, political, fiscal, social, physical, and social environments?
- Share your experience - Write up what you learned and communicate it with your peers.
- If the process was successful, then go to Step #1 - If you answered yes to many of the questions in Step #6, then repeat the process but this time consider: 1) adding journal article literature other than open access content, and 2) working with other institutions (libraries, consortiums, computing centers, etc.) in order build a bigger community. For better or for worse, the necessary body of literature includes licensed materials, and remember, you are not alone in your efforts.
- If the process was not successful, then consider Plan B - If you answered no to many of the questions in Step #6, then investigate alternative means for merging your book holdings, institutional repository data, and article/etext literature into a single index. This is described in more detail in the following section.

lunch |

lunch |

lunch |
The process outlined above is just that, an outline. You will have to fill in the details, but like any good recipe or folk song, the process is simply intended to be a framework. While the hows of librarianship are changing, they don't make significant changes annually. How long did it take for the Internet to catch on? A year? I don't think so. Even if the process is deemed a failure you and your team will come out a winner. You will have learned a broad range of new skills and applied them to the current environment. These skills will be applicable to future problems. The process will inform you in regards to future decisions. You will have made an investment in your personnel -- your most valuable resource.
Plan B
It is quite possible the do-it-yourself creation and maintenance of an index to local book holdings, institutional repository content, and articles/etexts is not feasible. This may be true for any number of reasons. You may not have the full complement of resources to allocate, whether that be time, money, people, or skills. You and your library may have a set of priorities forcing the do-it-yourself approach lower on the to-do list. You might find yourself stuck in never-ending legal negotiations for content from "closed" access providers. You might liken the process of normalizing myriads of data formats into a single index to Hercules cleaning the Augean stables.

technical expertise |

money |

people with vision |

energy |
If this be the case, then the purchasing (read, "licensing") of a single index service might be the next best thing -- Plan B. In such a scenario a middle man will negotiate the acquisition of content from a variety of content providers. This is akin to collection development. The content will be sent to or harvested by the middle man in any number of formats and mediums. This is close to acquisitions and preservation. The middle man's next task will be to normalize the content and index it. Think cataloging and the organization of information. The middle man then will ask for the metadata describing library catalog holdings and institutional repository records. This will be merged with the index. Finally, the middle man will sell access to a Web interface to the index and/or access to an application programmer interface (API) allowing you to create your on Web interface. Think dissemination and public service.
Given your environment and circumstances, Plan B may be more practical and realistic. It is nice to have choice.
Do-it-yourself and Plan B compared
Neither the do-it-yourself approach nor Plan B is perfect. There are strengths, weaknesses, opportunities, and threats in both.
Both will require people and time to implement, but the do-it-yourself approach is likely to be more expensive in this regard and require skills not readily available. On the other hand, Plan B will necessitate an on-going fiscal responsibility with few long-lasting, tangible returns. This will add up to a considerable sum after a number of years. At least with the do-it-yourself approach you will garner reusable expertise and own the indexed content. ("Lot's of copies keep stuff safe.") Plan B offers immediate benefits in terms of economies of scale since publishers are more likely to license content to a few middlemen as opposed to hundreds of individual libraries. Neither approach will be comprehensive. For any number of reasons, some content will never appear in either implementation. Even if you do successfully implement a single index to your content -- a "Web-scale" index, it will necessarily be normalized into a single all-encompassing data structure. Therefore, some specialized searching capabilities will be lost, and consequently you may not realize as many cost benefits as you may think. To what degree are you willing to drop existing subscriptions with the implementation of your "Web-scale" index?

comprehensiveness |

economies of scale |

normalization |

resources |
Don't get me wrong. The implementation of a single index to your content is definitely a step in the right direction. At the very least it has the potential of reducing the number of information silos in your library, as well as reducing the number of user interfaces you and your library need to support. Just as importantly, it comes closer to people's expectations when it comes to search. One box. One button. Relevancy ranked -- smart and intelligent looking -- output.
Web-scale indexes and "next generation" library catalogs

right direction |
Much of our time is spent providing access to content. Discussions of Web-scale indexes and "next generation" library catalogs are the evolutionary products of these efforts.
Yet I say access is no longer the primary problem to be solved for libraries. Access is not the name of the game. With the advent of globally networked computers the access to information has never been easier. Yet wew continue to drink from the proverbial fire hose. Instead of providing the means to acquire content, we need to be thinking about ways of making content more useful. How can we "save the time of the reader"? How can we make it easier for the learner, instructor, or scholar to accomplish their work quicker and more efficiently?
To my mind, the answer to these questions lie in the implementation of services against content. Besides just giving content to our clientele, we ought to provide the means for our clientele to do something with the content. This doing is exemplified in action word such as: annotate, cite, compare & contrast, create different version, create flip book, create tag cloud, concordance, do morphology, find opposite, find similar, graph, hilight, incorporate into syllabus, map to controlled vocabulary, plot on a map, print, purchase, rate, review, save, search, share, summarize, tag, trace author, trace citation, translate, etc.
None of these services against content are possible unless you have the content. With the increasing availability of content in digital form, such things are entirely possible. These things, in my opinion, are the hallmark of a "next generation" library catalog. Search -- facilitated by an index, not a database -- is only part of the issue. Because librarians are expected to know the characteristics of their clientele, librarians have a leg up on the Google's of the world. Because we are expected to be in the same context as our users, we should be able to put the content they acquire into their context. Again, the implementation of "Web-scale" indexes is the step in that direction.

"Thank you" |
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: These remarks originally appeared on the University of Notre Dame's website at http://www.library.nd.edu/daiad/morgan/musings/web-scale/, and they were a part of a webcast called Returning the Researcher to the Library: Defining Web-Scale Discovery sponso
Date created: 2009-08-13
Date updated: 2009-08-22
Subject(s): presentations; indexing; librarianship;
URL: http://infomotions.com/musings/web-scale/