 My personal TEI publishing system
My personal TEI publishing system
This text describes a TEI publishing system I created to disseminate my writings. (If you are looking for <teipublisher> then go to http://teipublisher.sourceforge.net/docs/.)
Introduction
I make no bones about it. I'm not a great writer. On the other hand, over the years, I have written more stuff than the average person. Furthermore, I certainly don't mind sharing what I write whether it be prose, the handout of a presentation, or the code to a software program. I've been practicing "green" open access and open source software long before the phrases were coined. As a librarian, it is important for me to publish my things in standard formats complete with rich meta data. Additionally, I desire to create collections of documents that are easily readable, searchable, and browsable via the Web or print.
In order to accomplish these goals I decided to write for myself a rudimentary TEI publishing system, and this text describes that system.
Ironically, this isn't my first foray into this arena. When the Web was still brand new (as if it still isn't), I wrote a simple HTML editor using Hypercard called SHE (Simple HTML Editor). Later, I wrote a database program with a PHP front-end . Both systems created poorly formatted HTML, and both of those systems worked for a while. I suspect my current implementation will not stand the test of time either, but the documents it creates are not only well-structured but validate against TEI and XHTML DTD's. The system also supports robust searching capabilities and dissemination of content via OAI.
MySQL database
The heart of the system is a MySQL database, and the code I've written simply does input/output against this database. The database's structure is simplistic with tables to hold authors, subjects, templates, stylesheets, and articles. There are many-to-many relationships between authors and articles as well as subjects and articles. There are simple one-to-many relationships between templates and articles as well as stylesheets to articles. The scheme also includes a rudimentary sequence table in order to not mandate the use of MySQL's auto_increment feature.
Musings.pm
While the database is the heart of the system, a set of object-oriented Perl modules reduces the need to know any SQL. The Perl modules make life much easier, and I call them Musings.pm . Each module in the set corresponds to a table in the database, and each module simply sets and gets values, saves and deletes records, and supports global find routines. After all that is all you can do with databases: 1) create records, 2) find records, 3) edit records, and 4) delete records.
Administrative interface
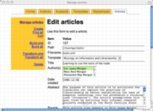
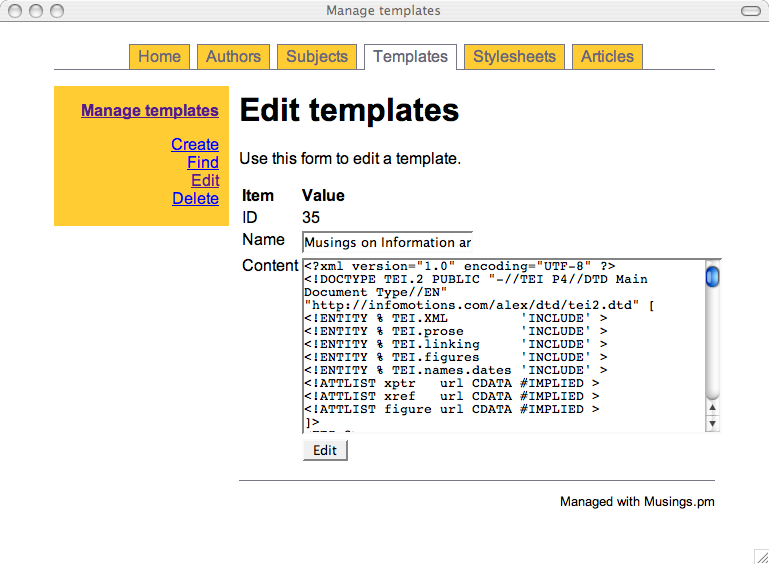
Once the modules were written I was able to write an administrative interface in the form of a set of CGI scripts. Like the modules, there is one CGI script for each of the tables in the database. For example, the authors.cgi script allows me to add, find, edit, and delete author information -- an authority file in library parlance. The subjects.cgi script allows me to manage a set of controlled vocabulary (subject) terms used to classify my articles. The templates.cgi facilitates the maintenance of TEI skeletons. These skeletons contain tokens like ##AUTHOR## and ##TITLE##, and these tokens are intended to be replaced by real values found in the other tables in order to create valid TEI output.
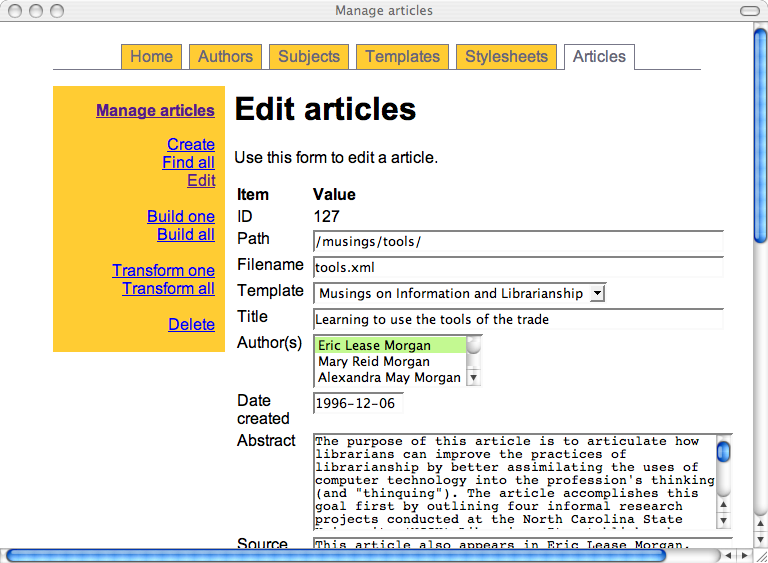
The articles.cgi script is the most complex. It allows me to enter things like title, date created, abstract, and changes information. It also allows me to select via pop-up menus subject terms, authors, templates, and stylesheets to associate with the article.
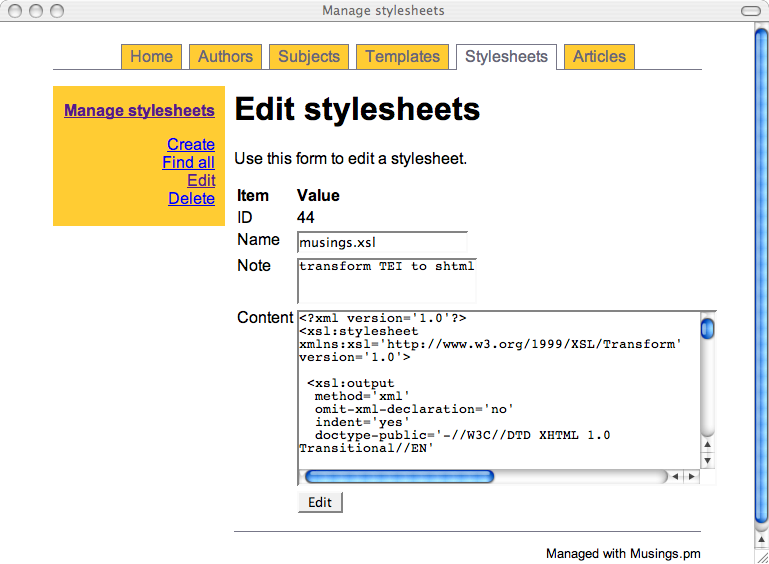
Once all the necessary information is entered, I use article.cgi's "build" function to amalgamate the meta data and content with the associated template. The resulting XML is then saved locally. I then use the script's "transform" function to change the saved XML into XHTML through the use of an XSLT stylesheet. (The stylesheet, like the template, is managed through a CGI script.) The XHTML files are complete with Dublin Core meta tags. Throughout this entire process I am careful to validate the created documents for not only well-formedness but validity as well.
It is important to note the administrative interface is more of a publishing system and is in no way an editor. Each of the parts of the system (authors, subjects, templates, stylesheets, articles) are expected to include XML mark-up. It is up to me to mark-up the content before it gets put into the system. To accomplish this, I use a text editor (BBEdit) on my desktop machine, and BBEdit allows me to create a "glossary" or set of macros to mark-up the documents easily. The administrative interface simply glues the parts of the system together and saves the result accordingly.
Here is a sample of screen shots from the administrative interface:
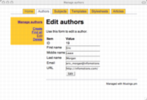
manage authors |
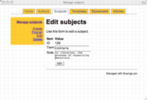
mange subjects |
{kind=link}
{kind=link}
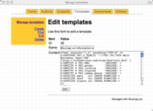
manage templates |
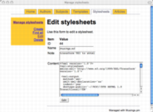
manage stylesheets |
manage articles |
{kind=link}
{kind=link}
{kind=link}
Indexing
As the size of any collection grows so does the need for search functionality, but free text searching against relational databases is as pain. Such functionality is not really supported by relational database applications. Creating an index against the content of the database (or a set of files) make searching much easier. Consequently, I provide search functionality through an indexer.
Currently, my favorite indexer is swish-e . It supports all features librarians love: phrase searching, Boolean logic, right-hand truncation, nested queries, field searching, and sorting. Swish-e excels at indexing HTML files and/or XML files. During the indexing process you can specify what HTML elements are to become possibilities for field searches. I specify the Dublin Core meta tags.
Thus, after I create my XHTML documents, I index the entire lot using swish-e.
User interface
I have now created a set of stand-alone, well-formed, valid TEI and indexed XHTML documents. What is then needed is a user-interface. Because all of the documents have been described with a set of controlled vocabulary terms, I can create a list of these terms and then list the articles associated with each term -- a subject index. Since each article is associated with a date, I can list my articles in reverse chronological order. Since each article has a title, I can list them by alphabetically -- a title index. Since the entire corpus is indexed, I can provide a search interface to the content.
To make this happen I wrote one more CGI script, the system's home page . This page includes an introduction to the collection, a search box, and a list of three links to title, date, and subject indexes. These indexes are created dynamically taking advantage of Musings.pm. If I got fancy, I could count the number of times individual articles where read and provide a list of articles ranked by popularity. Similarly, I could watch for types of searches sent to the system and create lists of "hot topics" as well.
Now here's a tricky thing. I know the subject terms of each article. I know the content has been indexed with swish-e. Therefore I know the exact swish-e query that can be used to find these subject terms in the corpus of materials. Consequently, in the footer of each of my documents, I have listed each of the article's subject terms and marked them up with swish-e queries. This allows me to "find more articles like this one."
As you may or may not know, an index is simply a list of words associated with pointers to documents. Swish-e provides a means of dumping all the words to standard output. By exporting the words and feeding them to a dictionary program, I can create a spell-checker. I use Aspell for this purpose. Consequently, when searches fail to produce results, my user interface can examine the query, try to fix mis-spellings, reformat the query, and return it to the end-user thus providing a "did you mean" service a la Google.
Lastly, I was careful to include the use of cascading stylesheet technology into the XHTML files. Specifically, I introduced a navigation system as well as a stylesheet for printed media. This provides the means of excluding the navigation system from the printed output as well as removing the other Web-specific text decorations.
Here are number of screen shots from the user interface:
home page |

title index |
subject index |
date index |
search result |
a page |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
OAI
The documents of my collection are mere reports written against the database. There is no reason other reports can not be written as well, and one of those report types are OAI streams. Again, using the Musings.pm module, I was able to write a very short program that dumps all of my articles to sets of tiny OAI files. These files are saved to the file system and served to OAI harvesters through a simple, Perl-based OAI server called OAI XMLFile .
Conclusion
Creating the infrastructure to publish my documents was rather time consuming, but once this infrastructure was in place, it made it very easy publish a great number of documents consistently and accurately. Here is the process I use to publish things:
- Have an idea.
- Write it down.
- Mark it up in TEI.
- Assign subject terms
- Make sure they are in the database.
- Add the TEI to the database -- do data entry.
- Build the file.
- Check it for validity.
- Transform it into XHTML.
- Check it for validity.
- Index the entire corpus.
- Create OAI reports.
- Go to Step #1.
Given this system, I am able to spend most of my time articulating my ideas and writing them down. Steps #3 through #12 require only about thirty minutes.
Sometimes I feel like Ben Franklin. He was a writer (a much better writer than myself). He owned his own printing press. (In fact he owned many of them across the colonies.) He also designed his own typeface. Not only that, he was Postmaster for a while. In short, he had control of the entire distribution process. With the advent of the Web, much of that same distribution process is available to people and institutions like myself. All that needs to be done is design systems that fit one's needs and implement them. Such things exemplify enormous opportunities for cultural heritage institution such as libraries, museums, and archives -- as well as individuals.
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This text was never formally published.
Date created: 2004-11-24
Date updated: 2005-03-31
Subject(s): TEI (Text Encoding Initiative); publishing; HTML (Hypertext Markup Language); XML (eXtensible Mark-up Language);
URL: http://infomotions.com/musings/publishing-system/