 Exploiting "Light-weight" Protocols and Open Source Tools to Implement Digital Library Collections and Services
Exploiting "Light-weight" Protocols and Open Source Tools to Implement Digital Library Collections and Services
Abstract
This article describes the design and implementation of two digital library collections and services using a number of "light-weight" protocols and open source tools. These protocols and tools include OAI-PMH (Open Archives Initiative-Protocol for Metadata Harvesting), SRU (Search/Retrieve via URL), Perl, MyLibrary, Swish-e, Plucene, ASPELL, and WordNet. More specifically, we describe how these protocols and tools are employed in the Ockham Alerting service and MyLibrary@Ockham. The services are illustrative examples of how the library community can actively contribute to the scholarly communications process by systematically and programmatically collecting, organizing, archiving, and disseminating information freely available on the Internet. Using the same techniques described here, other libraries could expose their own particular content for their specific needs and audiences.
Ockham
Ockham [1] is a National Science Foundation (NSF) funded digital library project with co-PI's at Emory University, Oregon State University, Virginia Tech, and the University of Notre Dame. One of the primary purposes of the grant is/was to explore and implement programmatic methods for better integrating National Science Foundation Digital Library (NSDL) content into traditional library settings through the use of "light-weight" protocols and open source software. For our purposes, "light-weight" protocols are essentially Web Services like OAI-PMH (Open Archives Initiative-Protocol for Metadata Harvesting) and SRU (Search/Retrieve via URL). To fulfill these aspects of the grant, two testbed services were developed at the University Libraries of Notre Dame: the Ockham Alerting Service, and MyLibrary@Ockham. The following sections describe the purposes and steps taken to programmatically implement these services. It is our hope other developers will use these steps as a model for implementing services for their specific purposes and communities.
Ockham Alerting Service
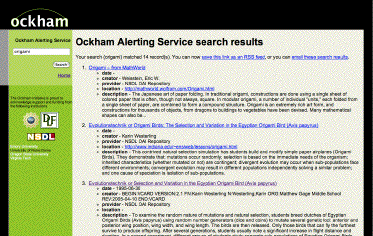
Figure 1. screen shot of Ockham Alert |
{kind=link}
The Ockham Alerting Service [2] provides a means for researchers to keep abreast of what is new in a particular OAI-PMH repository. This is how the system works:
- The most recent thirty days of records added to an OAI-PMH repository is harvested and cached to a local database.
- A report is written against the database including all the database's content, and the report is indexed with an indexer.
- An SRU server is implemented against the index.
- An SRU client is implemented against the SRU server.
- Search results are transformed from the returned SRU/XML and made available as HTML pages, RSS feeds, and/or email messages.
- Everyday content that is one day old is harvested from the OAI-PMH repository.
- Everyday content from the local cache that is older than thirty days is deleted.
- Go to Step #2.
Using this method, the local cache is constantly changing, and when users save the queries as RSS links in RSS readers, then users will see an ever-evolving list of newly accessible items from the OAI-PMH repository. Since the index is available via another "light-weight" protocol -- SRU -- other applications could be applied against the index that have yet to be discovered.
MyLibrary@Ockham
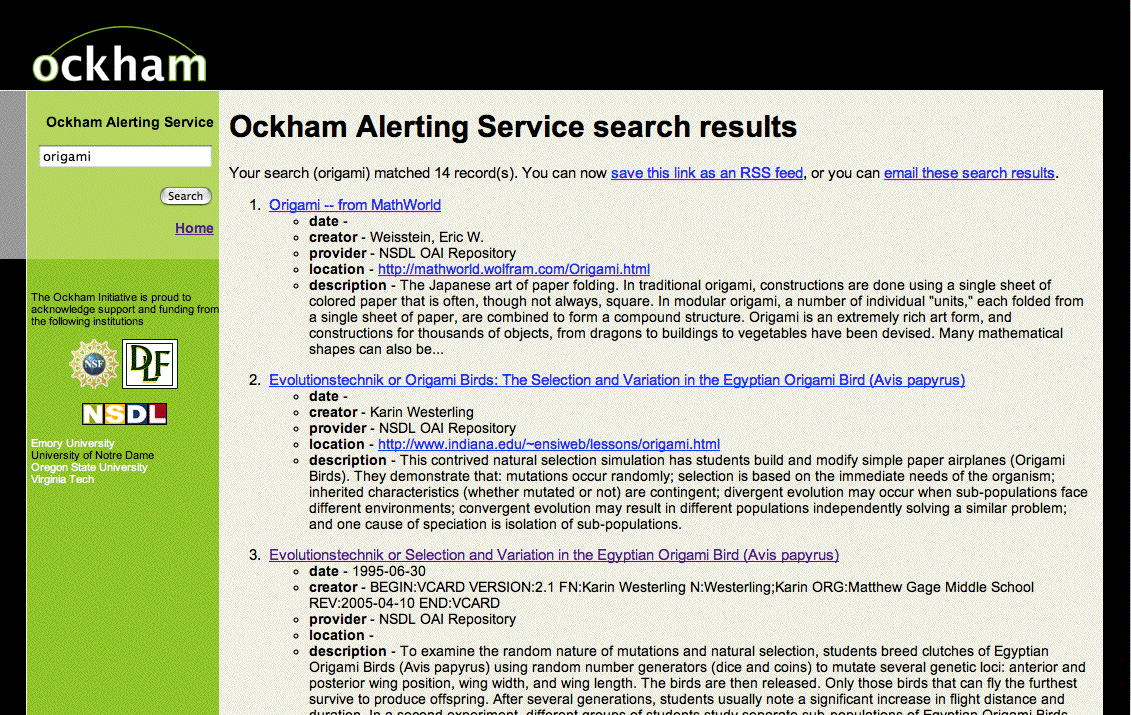
Figure 2. Screen shot of MyLibrary@Ockham |
{kind=link}
MyLibrary@Ockham [3] illustrates methods by which search results can be enhanced, making it easier for researchers to address the perennial problem of "finding more like this one".
A common approach to finding similar records in an index is "tracing" -- sometimes called "pearl growing" -- as described by Bates [4]. In this approach, users identify one or more pieces of metadata from an item of interest and search for other items with similar characteristics. For example, a user may want to find other items by the same author or with similar keywords. MyLibrary@Ockham takes this approach a few steps further by proactively generating canned searches based on the user's query and the resulting metadata records, as described by Morgan [5]. It does this through a combination of syntactical, semantic, and statistical analysis.
This is how it works:
- Entire OAI-PMH data repositories or sets are identified for collection.
- A classification system is articulated for the purposes of intellectual organization.
- The classification system is applied to the data to be collected.
- The OAI-PMH content is harvested, saved to a local cache, and each incoming record is enhanced according to the results of Step #3.
- Reports are written against the cache and indexed with an indexer.
- The resulting indexes are analyzed in two ways:
- All of the individual words from each index are used to create an index-specific dictionary.
- A term frequency-inverse document frequency score is computed against each term in the index for each record, and then each record is updated with the list of the five (5) most significant keywords.
- The indexes are made accessible via an SRU server.
- A specialized SRU client is implemented against the SRU server.
- As queries are received by the server, they are parsed into individual words and analyzed in two ways:
- The words are "spell-checked" against the local, index-specific dictionary, and the alternative spellings are packaged into the results.
- The words are applied against a local thesaurus, and the possible synonyms are packaged as well.
- The SRU client receives the results and transforms the SRU/XML into HTML.
The final output is more than a simple list of hits. First, each of the alternative spellings is hot-linked to search the current index. Second, any suggested thesaurus terms are hot-linked in the same way. Third, the statistically relevant keywords previously saved to each record are also hot-linked. Fourth, each of the relevant keywords is combined into a Boolean intersection ("and") query against the index. Finally, each record's identifier (URL) is marked-up to take advantage of Google's "related" syntax. In this way, users can search similar web sites using the Google search engine.
By comparing query terms to a locally created dictionary and a thesaurus, MyLibrary@Ockham is able to suggest alternative searches based on simple syntactical and semantic analysis. By generating lists of statistically relevant keywords from each record, the system can overcome the lack of a consistently applied controlled vocabulary from the incoming OAI-PMH data. Through these means MyLibrary@Ockham proactively provides the means for the researcher to "find more like this one."
"Light-weight" protocols and open source tools
One of the goals of Ockham is to demonstrate how "light-weight" protocols and open source software can be used to implement modular digital library collections and services. "Light-weight" protocols are characterized as protocols that are easy to implement, and they exemplify a philosophy of doing one thing and doing it well. HTTP is a good example. OAI-PMH is another. We advocate SRU as a third.The following sections describe in greater detail how the protocols and various pieces of open source software have been employed in the Alerting Service and MyLibrary@Ockham. Their implementations mirror most of the fundamental processes of librarianship: collection, organization, preservation, and dissemination.
Creating collections with OAI-PMH
OAI-PMH [6] is used to harvest metadata records from selected repositories and sets.
For the Alerting Service, we regularly harvest content from a single repository: the National Science Foundation OAI Data Repository. Our OAI-PMH harvester is written in Perl using modules available from CPAN [7]. As the content is harvested, it is parsed and cached to a (MySQL) database essentially composed of tables with many self joins. This is very simple and elegant. The database schema should prove useful for any OAI-PMH metadata scheme.
The content for MyLibrary@Ockham is derived from many OAI-PMH repositories and sets. For the purposes of the grant, most of the content comes from NDSL (National Science Digital Library) projects and is supplemented with additional repositories of interest. Again, the harvester is written in Perl but uses an XML file with a locally defined DTD as input. This configuration file denotes from what repositories/sets to harvest as well as what date ranges to use to limit input. This functionality enables the system to harvest only newly added items from repositories, reduces data duplication, and increases network efficiency. The XML file also denotes how the harvested content will be organized by the system, which is described below.
Organizing collections with MyLibrary
MyLibrary is used to cache and logically organize the content of MyLibrary@Ockham.
MyLibrary [8] is a set of object-oriented Perl modules designed to do input/output against a specifically shaped relational database for the purposes of implementing digital library collections and services. At the core of the database is a resources table with a many-to-many relationship to a terms table. The resources table is made up essentially of Dublin Core elements. The terms table, in combination with a facets table, allow information resources to be logically organized with one or more two-level hierarchies -- facet/term combinations. When compared to the implementation of one large, infinitely deep hierarchy, the facet/term approach has proved to be very easy to implement and extraordinarily flexible.
Facets are broad headings. The easiest facet for librarians to get their minds around will quite likely be a subjectsfacet (the "aboutness" of an item). Examples of subjectsfacets include astronomy, philosophy, or mathematics. Another example of a facet might be formats(the physical manifestation of an item). Associated terms for a formatsfacet might include books, journals, or musical scores. A third example includes audiences with possible term values such as undergraduate student, graduate student, faculty, or staff. MyLibrary allows the implementor to create as many facet/term and values combinations as they desire.
By combining one or more facets/terms with Dublin Core elements, it is possible to classify and organize things in a MyLibrary database with ease. For example, the Alex Catalogue of Electronic Texts might be described in a MyLibrary database like this:
title: Alex Catalogue of Electronic Texts
creator: Infomotions, Inc.
identifier: http://infomotions.com/alex/
description: A collection of "great" books from American and English literature
as well as Western philosophy
facet/term: Subjects/Literature, American
facet/term: Subjects/Literature, English
facet/term: Subjects/Western philosophy
facet/term: Formats/electronic texts
facet/term: Audiences/undergraduate students
This same approach has been applied to entire OAI-PMH repositories and sets. For example, each record harvested from Project Euclid has been described in MyLibrary@Ockham something like this:
title: On stationary stochastic flows...
identifier: http://ProjectEuclid.org/getRecord?id=euclid.aoap/1019487351
description: We consider a random surface Phi in mathbb tessellating the space
into cells and a random vector field u which is...
facet/term: Formats/Articles
facet/term: NSDL OAI Repository sets/Project Euclid
facet/term: Subjects/Mathematics
As OAI-PMH data is harvested for MyLibrary@Ockham, each record is cached to the underlying database using its Dublin Core elements and supplemented with facet/term combinations [9]. The MyLibrary Perl API allows us to query the database and create reports matching facet/term combinations such as subjects/chemistry or subjects/physics or subjects/astronomy. The records of these reports are then passed on to an indexer to create an index for searching.
Indexing collections with Swish-e and Plucene
Swish-e [10] and Plucene [11] are used to index the content of the Alerting Service and MyLibrary@Ockham, respectively.
While the content of our services is cached in relational databases, relational databases do not lend themselves very well to free-text searching and relevance ranking -- searching features increasingly expected by the user community. Consequently, the content of our services is piped to indexers, and search results return keys to individual records. These keys are then used to extract the necessary information from the underlying databases.
Swish-e is used to index the content of the Alerting Service. To do this, a report is written against the database in the form of an XML stream and sent to the Swish-e program. The program uses a configuration file to parse the stream into fields and facilitate field searching later on. Swish-e supports a subset of CQL (Common Query Language) necessary for SRW/U, but the subset is more than satisfactory for our needs. Searching the index is done through a Perl API to the Swish-e C libraries.
Plucene is a Perl port of the increasingly popular Lucene [12] indexer and search engine. It is used to index the content of MyLibrary@Ockham. Unlike Swish-e, Plucene supports multi-byte characters, incremental indexing, and a larger subset of the necessary CQL syntax, namely proximity searching. Additionally, Plucene is more of a toolbox instead of a computer program; it is a set of functions, subroutines, and methods enabling the computer programmer to build their own indexing and searching application. These characteristics make Plucene more flexible but also more complicated.
Analyzing indexes and enhancing search with ASPELL, WordNet, and statistical analysis
To enhance retrieval in MyLibrary@Ockham we use GNU ASPELL [13] to suggest alternative spellings, WordNet [14] to suggest possible synonyms, and a mathematical technique to compute statistically relevant keywords. ASPELL is an open source dictionary application/library with a Perl API. Once populated with content, ASPELL can compare a given string to the words in its database and return other strings with similar shapes -- spell checking functionality. We employ this technique [15] in our system as follows:
- A dump of all the individual words in a particular index is written to a file.
- The file is fed to ASPELL to create an index-specific dictionary.
- As queries are received by the server, they are parsed into individual terms and "spell checked" against the dictionary. Alternative spellings are returned.
- A subset of the alternative spellings, based on the value of the SRU x-spell parameter (described below), is packaged up in the SRU/XML response.
Since the dictionary is built from words in the index, the spell checking process will only recommend words in the dictionary. Consequently, every single suggestion should have at least one record associated with it.
WordNet is a lexical reference system developed by the Cognitive Science Laboratory at Princeton University. English nouns, verbs, adjectives and adverbs are organized into synonym sets, each representing one underlying lexical concept, and the synonym sets are linked with different relations. WordNet is distributed as a data set. There are applications for reading and writing to the data set, as well as at least two Perl APIs.
The use of WordNet in our system is very similar to use of ASPELL:
- As queries are received by the server, they are parsed into individual words.
- Each word is applied to the thesaurus, and synonyms are returned.
- Depending on the value of the SRU x-thesaurus parameter (described below), a percentage of the synonyms are packaged into the SRU/XML response.
In more technical literatures, such as the literature of theses and dissertations, this technique is not sufficiently optimal because the thesaurus is more or less limited to general English. However, it is possible to build a thesaurus for each specific domain and address this limitation.
A term frequency-inverse document frequency (TF-IDF) technique [16, 17] is used to calculate term relevancy.
In order to help end-users find items similar to the ones in which they are interested, it is necessary to classify relevance information by analyzing content of a set of documents (a corpus). Content analysis is a typical research area in information retrieval, and it is related to text mining and text analysis research. The goal of this research is to identify users' interests for information retrieval automatically. Much research has been done to approach this task from two perspectives. Some research focuses on the syntactic, semantic, and pragmatic analysis of natural language text. In this approach, it allows users to retrieve information based on meaning of words. Other research employs statistical methods for text analysis. Relevancy is deduced from the comparison of the frequency of words in a document with the frequency of the same words in a corpus.
In our system, statistical recommendations for a particular query are based on the calculation of a TF-IDF score for each of the words in the documents. This score is popular in information retrieval for analyzing relevance, and the score for each of the words (i) in a document (j) is defined as:
score[i, j] = tf[i,j] * log2(N/df[i])
in which N is the total number of documents in a corpus, df[i] is the number of documents containing word i, and tf[i,j] is the number of occurrences of i in document j.
A common term (word) that occurs in all documents is not a good candidate for representing the content of documents, it has inverse document frequency 0. A term that occurs often in one document but in few documents overall will have a high inverse document frequency. Therefore, that term has a high TF-IDF score and is thus a strong candidate for characterizing the content of the document.
This is the method used to compute the list of relevant keywords in MyLibrary@Ockham:
- A list of all the words from a particular index is created.
- Stop words and words with lengths of less than three (3) characters are removed.
- The number of documents containing each word i (df[i]) and the total number of documents N in the index is computed with a Perl script.
- The inverse document frequency of each word i, idf[i] = log2(N/df[i]), is computed by taking the log of the ratio of N to the document frequency of i (df[i]). The idf value is stored in the local file system for higher performance since idf value of each word in a particular index is a constant.
- The description and the title fields in each document j are parsed into index words, which is a similar process to the process of creating the index. Stop words and words with lengths of less than three (3) characters are removed.
- The term frequency of each word i in a document j, tf[i,j], is computed. Words occurring in the title field are assigned a higher weight (a word i in the title is count two times for each of its occurrence) than words occurring in the description field.
- TF-IDF score is computed for each word in a document j. Words are sorted by the TF-IDF score. The first five words with highest TF-IDF score, which are best candidates for characterizing the content of document j, are then stored in the MyLibrary database.
- Steps #5 through #7 are repeated for each document in an index.
- Steps #1 through #8 are repeated for each index.
TF-IDF is easy to implement and almost sufficient to capture the content of the document by extracting individual words. The stemming technique for choosing particular words is not used in the current implementation. There are many different formulae and improvements for calculating the TF-IDF score [18] besides the simple version used in our implementation. Keyphrases, however, are more accurate than keywords for representing characteristics of a document. The KEA system [19] and Turney's Extractor [20] are two candidates that can be used to extract keyphrases. They both use supervised machine learning techniques.
Searching indexes and disseminating content with SRU
SRU makes the indexes of the Alerting Service and MyLibrary@Ockham accessible via the Internet and a user's Web browser.
SRW (Search/Retrieve via the Web) and SRU [21] are "brother and sister" Web Service-based protocols for searching Web-accessible databases/indexes. SRW is implemented using SOAP (Simple Object Access Protocol). SRU is implemented in a REST-like (Representational State Transfer) manner. While the transport mechanisms of SRW and SRU differ, the content encapsulated in their messages is the same. The paper by Sanderson et al. [22] contrasts the approaches for these two protocols and dicusses possible architectures to facilitate information retrieval. Morgan [23] describes SRU in greater detail.
Our SRU servers make use of a Perl module [24] available from CPAN. The SRU server for the Alerting Service is straightforward. Queries are received, converted into Swish-e syntax, and searched against the index. The resulting keys are used to extract information from the underlying database, and the results are returned as an XML stream to the client. The client transforms the SRU/XML into HTML, RSS, and/or email messages. This is done with a few XSLT stylesheets.
The SRU client for MyLibrary@Ockham is simpler than the Alerting Service client [25]. On the other hand, the server uses the SRW/U extension mechanism for supporting our spelling and thesaurus services. More specifically, the server can accept an extra parameter called x-spell with integer values ranging from 0 to 3. The number of alternative spellings is calculated as a percentage of total suggested words returned from the Perl interface to ASPELL. Similarly, an extra parameter named x-thesaurus uses the same integer values to denote the number of synonyms to return, and it too is calculated as a percentage of the total suggested synonyms returned from the Perl interface to WordNet. Finally, since MyLibrary@Ockham hosts many indexes, we implemented an extra parameter called x-database with a value denoting the index to search.
When the SRU/XML is returned to the client, an XSLT stylesheet is employed to transform the results into HTML. This is where the alternative spellings, suggested synonyms, statistically relevant keywords, and URL are hot-linked to search the current index or Google. When a large number of records is returned, it is convenient to display them in several pages. Our paging mechanism is implemented using the startRecord and maximumRecords parameters as defined by SRW/U. The startRecord parameter gives the position of the first records to be returned, and the maximumRecords parameter gives the number of records that the client wants to receive.
Conclusion and Discussion
In this article, we describe two services that demonstrate how open source tools and Web Services techniques can be used for implementing digital library collections and services. We expect that other institutions and libraries may use the same techniques to implement other services against their content.
The Ockham Alerting Service functions correctly but not perfectly. The biggest problem is with the definition of "new" items. Just because items have been added to the repository in the past day does not mean the items were recently written. The most visible problem is character encoding. For an unknown reason many records contain unrecognizable characters, and we are not sure if this stems from the harvesting procedure or the storage mechanism. The service could use some enhancements allowing the user to define the desired age of links returned to them. Multiple OAI-PMH repositories could be included into a single interface. The report writing process could also be improved to take advantage of the multiple titles, identifiers, etc. found in many of the OAI-PMH records.
MyLibrary@Ockham also functions correctly, but it too is not perfect. Like the Alerting Service, MyLibrary@Ockham suffers from character encoding problems. More investigation is definitely needed here. Because individual records in the underlying database can be classified with any number of facet/term combinations, and because reports generated against the database combine sets of records in a Boolean union ("or") manner, records are often duplicated in the indexes. A technique needs to be implemented for removing these duplicates. Calculating statistically significant keywords is seamless, but combining each of the five (5) most relevant keywords into a Boolean intersection ("and") search is often too restrictive and rarely identifies more than the currently displayed record. Additionally, phrases are more often seen as more relevant, and our implementation should explore creating relevant phrases as opposed to simply keywords. This needs be addressed in the spelling system as well; the system only spell checks single terms and does not create multi-term queries. The spelling check and finding synonym functions are embedded within the SRU server using extended parameters. Exporting these functions to separate Web Services should be more convenient, accessible, and usable by the whole community but would also increase network latency.
In addition to the correctly functioning systems, other things have been accomplished. For example, these projects sponsored the initial creation of the SRU Perl module. Others will be able to use the module to create and implement their own SRU clients and servers. In addition, the projects have successfully demonstrated how "light-weight" protocols and open source software can be used to create digital library collections and services. Moreover, many of the functions of these collections and services can be interchanged. Other harvesting applications could be employed. One database schema can be replaced with another. One indexer can be interchanged with a second. Because both services output SRU/XML, the returned information contains no presentation layer, which makes it easy to transform the content for other outputs and to use the content in ways not necessarily imagined. This same technique -- the use of Web Services or "light-weight" protocols -- is employed internally by Fedora [26] and enables it to function as the foundation for many types of digital library collections and services.
With the advent of the Internet, people's expectations regarding access to information are radically changing. In academia, one example includes the relatively new ways of scholarly communication via pre-print servers, open access archives, and institutional repositories. Libraries, especially academic libraries, are about the processes of collection, organization, preservation, and dissemination of data and information. If the data and information of these processes is available on the Internet, then in order to stay relevant and not be seen as a warehouse of unused materials, libraries need to exploit ways of applying these processes to Internet content. The tools -- "light-weight" protocols and open source software -- are readily available. The Ockham Alerting Service and MyLibrary@Ockham are examples, and we hope models, of how these processes can be implemented.
Acknowledgments
The authors would like to acknowledge Anna Bargallo Bozzo of the Universitat Pompeu Fabra who worked with us for a few weeks this past spring to flesh out the facets and terms used in MyLibrary@Ockham.
Notes and references
[1] Ockham, <http://ockham.org/>.
[2] Ockham Alerting Service, <http://alert.ockham.org/>.
[3] MyLibrary@Ockham, <http://mylibrary.ockham.org/>.
[4] Bates, M. "Information Search Tactics." Journal of the American Society for Information Science, 30, no. 4 (1979): 205-14.
[5] Morgan, E. "What's More Important: The Questions or the Answers?" Computers in Libraries, 19, no. 5 (1999): 38-39+.
[6] Open Archives Initiative - Protocol for Metadata Harvesting (OAI-PMH), <http://www.openarchives.org/>.
[7] The Perl module named Net::OAI::Harvester, written by Ed Summers, is used as the basis of our harvesting application. See <http://search.cpan.org/dist/OAI-Harvester/>.
[8] MyLibrary, <http://dewey.library.nd.edu/mylibrary/>.
[9] You can see exactly how the facets and terms are implemented in MyLibrary@Ockham, as well as the numbers of records associated with each facet/term combination, see <http://mylibrary.ockham.org/?cmd=facets>.
[10] Swish-e, <http://swish-e.org/>.
[11] Cozens, Simon. Find What You Want with Plucene. O'Reilly Perl.com (2004). Available at <http://www.perl.com/pub/a/2004/02/19/plucene.html>.
[12] Lucene, <http://lucene.apache.org/java/docs/>.
[13] GNU Aspell, <http://aspell.sourceforge.net/>.
[14] WordNet, <http://wordnet.princeton.edu/>.
[15] Bill Mosely, the primary developer of Swish-e, was the person who first suggested this spell checking technique to the authors.
[16] TF-IDF (from Wikipedia), <http://en.wikipedia.org/wiki/Tf-idf>.
[17] Salton, G., and C. Buckley. "Term Weighting Approaches in Automatic Text Retrieval." Information processing and management24, no. 5 (1988): 513-23.
[18] Nottelmann, H., and N. Fuhr. "From Retrieval Status Values to Probabilities of Relevance for Advanced IR Applications." Information retrieval6, no. 3-4 (2003): 363-88.
[19] Witten, I. H., G. W. Paynter, E. Frank, C. Gutwin, and C. G. Nevill-Manning. "Kea: Practical Automatic Keyphrase Extraction." Proceedings of Digital Libraries '99(1999): 254-56. Available at <http://www.nzdl.org/Kea/>.
[20] Turney, P. "Learning Algorithms for Keyphrase Extraction." Information retrieval, 2, no. 4 (2000): 303-36. For more about Extractor, see <http://www.extractor.com/>.
[21] SRW-Search/Retrieve Web Service, <http://www.loc.gov/z3950/agency/zing/srw/>.
[22] Sanderson, R., J. Young, and R. LeVan. "SRW/U with OAI Expected and Unexpected Synergies." D-Lib Magazine, 11, no. 1 (2005). Available at <doi:10.1045/february2005-sanderson>.
[23] Morgan, E. "An Introduction to the Search/Retrieve URL Service (SRU)." Ariadne, no. 40 (2004). Available at <http://www.ariadne.ac.uk/issue40/morgan/>
[24] Our SRU servers are based on a set of Perl modules, originally written by Ed Summers and now maintained by Brian Cassidy. See <http://search.cpan.org/dist/SRU/>.
[25] An even simpler SRU client has been implemented against the MyLibrary@Ockham indexes. All that is needed is a relatively modern Web browser supporting XSLT transformations. See <http://mylibrary.ockham.org/simple/>.
[26] Fedora, <http://www.fedora.info/>.
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This article was originally published in D-Lib Magazine, volume 11, Number 10 (October 2005). Its DOI is doi:10.1045/october2005-morgan. Additionally, Xiaorong Xiang was the lead author of this article.
Date created: 2005-10-01
Date updated: 2005-11-13
Subject(s): articles; OCKHAM (Open Community Knowledge Hypermedia Administration and Metadata); Web Services; open source software;
URL: http://infomotions.com/musings/protocols-and-oss/