 Trip to Rochester to Learn about XC
Trip to Rochester to Learn about XC
On February 8-9, 2007 I had the opportunity to visit the University of Rochester River Campus and meet with a number of very smart people to discuss a thing called XC (eXtensible Catalog, extensiblecatalog.info). This travel log documents the experience.

stained glass window |

Universalist Church |
{kind=link}
{kind=link}
Background
People's expectations regarding the access to data & information have dramatically changed with the advent of the Internet. At the same time library software -- specifically, library catalog software -- has not kept pace with people's expectations. Relevancy ranking of search results is the norm. People want access to the full text of things, not just pointers to it. There is more to people's information needs than the things owned or licensed by a library. People desire "smart" one-box, one-button interfaces sans Boolean operators. Spell checking. Find similar items. People who used this also used that. What's new in the form of RSS feeds. The ability to review, comment, tag, and annotate. The creation on of "my" pages. Save my citations. Permanent and simple URLs. Access content from the campus-wide portal, courseware system, or my home page. Facilitate the authoring and publication process. Renew my items. Share my links. Send me the content. "Filtered" browsing a la faceted classification. Only show me the things that are available now. All of these things are increasingly available to users of the Web in general, but library software does not support them or operates only in selected information silos.
The XC initiative is hosted by the University of Rochester and led by a set of co-principle investigators: Ron Dow, Jennifer Bowen, Nancy Foster, and David Lindahl. Financial support is being and has been provided by the Mellon Foundation. XC is designed to resolve many if not most of the issues outlined above. It wants to partner with many institutions who posses the necessary skills (traditional library experience, graphic & user-centered design, software engineering, governance and business knowledge, etc.) to address the problems, articulate solutions, outline schedules, and finally implement solutions in long-term and sustainable ways.
The purpose the XC meeting was to discuss all of these things in greater detail.

Group XC |

Rush Rhees Library |

library movie |
{kind=link}
{kind=link}
The Event
Pascal Calarco and I started out early in the morning. When it was all said and done, we had ridden on two airplanes for forty-five minutes each, but it took us almost thirteen hours to get to where we were going. Delay. Delay. Delay. Typical. Typical. Typical. On the quirky side, we rode in a limousine with Christine Todd Whitman (a former governor of New Jersey) as we re-routed ourselves through Chicago. That evening we had a very nice dinner and experienced silent film entertainment at the Eastman House. First class.
The real event got started the next day in the Rush Rhees Library. It was attended by approximately thirty people from twenty institutions: Andrew Mellon Foundation, Ann Arbor District Library, California Digital Library, California State University, Consortium of Academic and Research Libraries in Illinois, Cornell University, Emory University, Georgia Institute of Technology, Georgia Public Libraries Service, Johns Hopkins University, Library of Congress, Massachusetts Institute of Technology, New York University, North Carolina State University, OCLC, Oregon State University, University of Aarhus (Denmark), University of California, Berkeley, University of California, San Diego, and the University of Notre Dame.
Phased approach
The first half of the meeting was devoted to introductions, outlines of future plans, discussion of metadata issues, and demonstrations. For example, the XC Project Overview consists of three phases. Phase 1 includes identifying potential partners in the project, deciding on metadata and software issues, and doing reviews of the literature. Phase 2 includes building software, working with partners, doing user research, and deploying software. Phase 3 includes doing maintenance of the software, supporting the software using an open source model, extending functionality, and developing sustainable support.
Metadata
Jennifer Bowen outlined some of their thoughts regarding metadata. For example, they hope to include both digital and non-digital items in XC. There will be need for multiple schemas describing different sets of content. "One size does not fit all." At the same time there will be the need for internal schemas, and they are leaning towards MODS, MADS, and METS. There is also a desire to FRBR-ize the content and provide faceted browsing. This will mean some restructuring of the data as it is incorporated into XC. They also hope to exploit OAI-PMH as well as OAI-ORE to both harvest content from remote sites as well as expose content from XC to outside communities.
A Cool demonstration
Of great interest was C4. This demonstrated prototype application worked a lot like the profession's desires for metasearch: 1) regularly dump the content of a library catalog, 2) parse the metadata to create "facets", 3) combine the content with non-library content such as things mirrored from the Web or institutional repositories, 4) index the content with a non-proprietary indexer, 5) provide Web-based access to the index, 6) display search results complete with cover art and integrated results from Google, blogs, etc, and 7) search commercial indexes/databases in the background using screen-scraping and federated search techniques. Just about everybody in the room vigorously nodded their heads in approval, but it is important to understand the vision for XC goes well beyond the demonstration of C4.
Proposed architecture
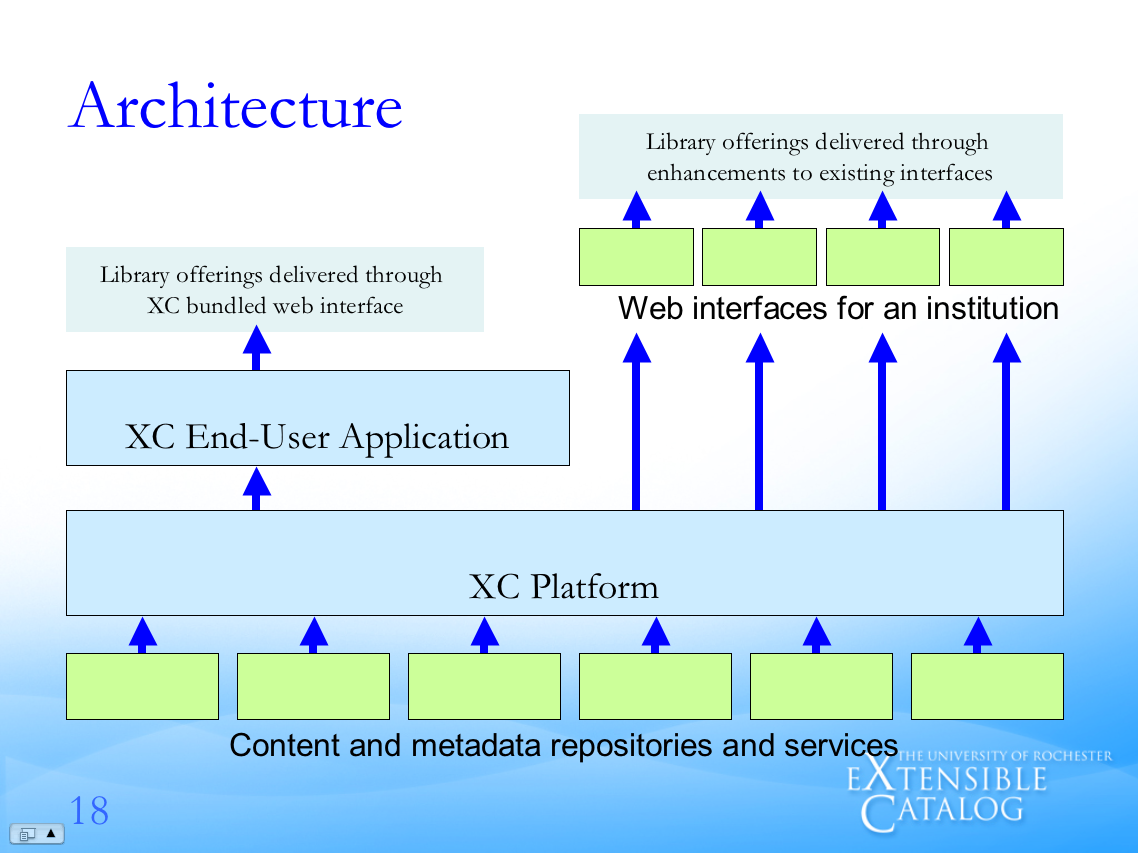
proposed architecture |
{kind=link}
This led into the presentation of a potential system architecture. It consists of four layers. The first layer is content. This content might come from any number of places including but not limited to: a library website, an integrated library system, a digital repository, a learning management system, RSS newsfeeds, or a metasearch engine.
The second layer is the XC "Platform" where the content is imported, stored, indexed, transformed into various metadata formats, exported, searched, protected against unauthorized access, and re-distributed.
The third layer is a "canned" Web browser interface to the Platform. This interface is analogous to the out-of-the-box interfaces provided by many of the profession's integrated library systems. This interface is intended for those institutions who do not have the desire or expertise to create the more customized interfaces in the last layer.
The last layer is a set of Web Services interfaces to the Platform allowing libraries to syndicate and incorporate XC (think, "library") content into things like a website, a content management system, a campus-wide portal, or a course management system. In today's world it is not about getting people to come to your website. Rather, it is about putting your content in their context and their websites. The Web Services interface satisfies this need.
Partners
XC is not intended to be built solely by the folks at Rochester. Instead they propose developing relationships with partners. There are five different types of partnerships:
- Advisory - Institutions who provide high-level guidance
- Component - Institutions who write ingest and export functions against the Platform
- Deployment - Institution who install the software for testing
- Implementation - Institutions who write software for the Platform
- User Research - Institutions who do basic research on patrons and their use of library and related technologies, along with user research linked to product development
Thus, each institution who partners with XC will have different sets of responsibilities. Since XC is designed to built on the output of existing integrated library systems, XC is looking to build relationships with at least one institution running each of the major systems.

eagle |

Ford Street bridge |

sunset |
{kind=link}
{kind=link}
{kind=link}
Discussion and summary
The second half the of the meeting focused on discussion of the proposed plans. For the most part people were impressed, but a few concerns seemed to bubble to the top. First, one person remarked on the scale of the project. Huge. Everybody agreed. The person advocated for a staged development approach picking off the "low hanging fruit". Another person piped up and advocated working on the more difficult parts of the project instead. "Individual institutions can work on the 'simpler' problems. Allow a group of people to work on the more difficult problems." I liked this second approach better. Another issue revolved around governance. Suppose Partner A thought a particular solution was most feasible, but Partner B thought a second solution was the better route to take. How would such issues get resolved? No answer was immediately forthcoming. Similarly, there were concerns regarding on-going support and business issues. What happens when the funding runs out? How will the project be sustainable? Again, these things are to be determined.
Personally, I sincerely believe XC is on the right track. For example, their track record regarding user-centered design in libraries is probably the best in the country. Their software and Web presence decisions are made on direct, measurable, and well-documented user behavior. Second, they have (or had) representatives on the RDA committee, thus their understanding of metadata issues is strong and their advocacy for the use of XML comes from a broad understanding of cataloging principles. Third, the systems architecture is well thought out. Modular. Componentized. Easily expandable.
Yes, building something like XC is a lot of work, but the time spent on such projects is not wasted. Not only will the end product be something that will solve immediate problems, but it will have a number of side benefits as well. It will bring collections, systems, acquisitions, and reference communities within libraries together on a single project. The process will increase the profession's knowledge of what computers can and cannot do. "This is not rocket surgery." It will enable libraries to be in greater control of their own data and information. It will enable libraries to be better equipped in meeting the changing expectations of their users. It will foster a greater number of standards-compliant implementations. It will enable libraries to bring together and provide interfaces to the wide range of library-related materials: things in catalogs, content from institutional repositories, items from special collections, scholarly materials freely available on the Web.
Communities and cooperation are a large part of what it means to be libraries. If libraries were to pool their resources and work together, I am certain the sum will be greater than its parts. XC is a manifestation of this idea.
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This essay was first "published" on my home page at the University Libraries of Notre Dame (dewey.library.nd.edu/morgan/musings/xc-2007/).
Date created: 2007-02-16
Date updated: 2007-03-03
Subject(s): travel log; OPAC (Online Public Access Catalogs);
URL: http://infomotions.com/musings/xc-2007/