 Open source software and libraries: A current SWOT analysis
Open source software and libraries: A current SWOT analysis
After more than ten years of listening and watching the library-related open source software, a number of things have changed. This presentation outlines some of those changes as well as outlines some of the strengths, weaknesses, opportunities, and threats of open source software. The presentation ends some ideas for a "next generation" library catalog -- services against texts. (This presentation is also availble in the form of a one-page PDF file, set of Powerpoint slides, and as an ebook.)
Much of my history
In one way or another, I have been writing computer programs since 1976. When I say my first computing experience was with punch cards it is the truth, but not in the way most people envision. In high school we were calculating the solutions to quadratic equations. Punch the cards. Feed them to computer about twice the size of a typewriter. Enter the inputs. Get the answer out, but I honestly don't remember the medium of the output. A tiny screen? A piece of paper? I don't recall.
A year or so later I took a BASIC programming class at the neighboring college. We were expected to write a dice game. I was a miserable failure. My game never worked. Instead I learned how to play Star Trek. A year after that, in college, I took another BASIC class, and again I didn't learn anything, but I did learn about the computer system in general. I was the first person at my college to hand in a word processed paper.
"You can't turn that in", my fraternity brother exclaimed.
"Why not?", I replied.
"It's not typed", he said.
"The purpose of typing the paper is not to learn how to use the typewriter, but rather to enable the professor to read what was written. My handwriting is terrible", I answered.
My brother looked at me with skepticism.
My professor said, "This is strange. The 'j' and the 'y' do not descend below the line. Hmmm..." He accepted the paper.
I did this for about three years, and I went on to be the first person to hand in my senior project in a word processed form. Years later it was fun went I visited my alma mater and looked at what I had produced after it had been microfilmed.
In 1983, while I was an unemployed college graduate, Texas Instruments was getting out of the personal computer business. My father said he would buy me a computer, and he did for about $100. I hooked it up to the television, saved data to a cassette tape recorder, and ran software through the use of plug-in cartridges. I had a chess game and music composition application. At the time I was a taxi driver, and I didn't know how much I was earning. Thus was born my first real computing need -- my first "itch". Using my driver's log as input, I wrote a computer program calculating all sorts of strange statistics. Dollars per hour. Miles per gallon. Tips per mile. Tips per gallon. Etc. In retrospect, I still don't know how much money I earned. I quit that job to work in a grave yard. I figured the graveyard was safer.
It was also during this time when I was really into astronomy, and a book came out called Practical Astronomy With Your Calculator. It described how to predict things like the position of the Moon, stars, and planets for any given date. I looked at the book and realized I could write a computer program to do the tasks instead of tediously using a hand-held calculator. I did. Three years later another book came out by the same author -- Practical Astronomy With Your Personal Computer.
By 1984 I needed a real job. I decided to become a librarian, and three things happened to me in library school. First I heard about something called "copyleft" and it appealed to me, but I didn't now why. Later I was to learn copyleft was coined by Richard Stallman to describe GNU. Second, while using my astronomy program I pressed the wrong button at the wrong time, and my program was completely erased! I spent the next eight to ten hours rewriting my program from scratch. I didn't get up. I didn't eat. I didn't drink. I was in some sort of zone. That was the first time such a thing happened. Scary. Third, I was working in Drexel University's Hagerty Library in charge of interlibrary loan lending.
"Remember, at the end of the year you will need to write an annual report", my boss said.
"What does that mean?", I asked.
"It means you will need to count up all of those little pieces of paper and tell me how many items were lent, returned, lost, etc.", she said.
"I hate counting things like that", and went away thinking.
Such was born my second big "itch". I saw this computer sitting in the corner -- an OCLC M300. In the morning I tickled it to print out the work I needed to do. In the late afternoon I tickled it again to describe what I had done. In between times it sat idle. I realized it could add a whole lot faster and more accurately than I could. It could also remember a whole lot better than I could. I resolved to write a computer program that generated my annual report daily. I did. I called it LENDS. It was at that time when I realized that computers could be used to do all sorts of library work.
By now it is 1986 and I was working as in intern at IBM. Robots delivered the mail. I made long distance telephone calls through satellites. I sent email back and forth to Sweden. I wrote a second program to generate my annual report daily. It was also at this time when I tried to sell LENDS. The process was painful. It was more trouble than it was worth. I gave up.
My first professional library job, in 1988, was as medical librarian in rural South Carolina. I was a circuit-rider librarian traveling around from hospital to hospital providing library services. At the time I was using a program called UltraCard to print my catalog cards. Upon inspection of the data created by UltraCard I noticed it was being saved as plain text. Easily parsable. I proceeded to write a computer program that read the data and implement an online catalog. I took a few hints from Fred Kilgour of OCLC about indexing as well as Walt Crawford on the structure of MARC. The program supported Boolean logic, free text searching, and rudimentary circulation. One of the strange things about this process was the purchasing of software "libraries". Modules that implemented things like pull-down menus as well as copy & paste functionality. All the while I kept asking myself, "Why are these people selling me these things? Why can't I have them for free?"
It was also during this time when I was awarded my first Apple Library of Tomorrow grant. They asked what I would do if I had a computer. I told them I would do online searches at the hospitals, send back requests via fax, get back the articles via fax, and reduce my turn-around time to hours instead of days. I got the grant and was given more hardware and more software than I knew what to do with. More importantly I wrote another set of software. Specifically, it:
- asked the user questions
- created a MEDLINE search on behalf of the user
- dialed into MEDLINE and executed the search
- downloaded the results
- presented the results to the user
- allowed the user to select items of interest
- dialed into DOCLINE and thus automated the ILL process
Pretty cool if you ask me.
By 1991 I out grew that job and moved on to North Carolina State University. I created all sort of hacks. A front-end to the library catalog. A front-end to OCLC's PRISM. A program managing a person's LISTSERV subscriptions. Most importantly, I learned about the "serials pricing crisis" and Mr. Serials was born. This suite of software subscribed to electronic journals via email. When new issues arrived they were stored in an electronic holding bin, and I received a notification telling me I had more work to do. I then wrote a program that parsed out the author, title, and bibliographic information and then saved the journal article on a Gopher server where the content was indexed with a program called WAIS. Fun with open access content before the phrase had been coined.
The folks from Apple Computer (specifically, Steve Cisler) came by again. This time they asked me to write a book describing how to use a Macintosh to implement World Wide Web servers. I did. The book is still available, and during the process I was expected to explain to Apple's lawyers why the content should be made freely available. They didn't seem to care very much one way or another. There wasn't any profit to be made from my book.
Around 1997 I wrote the first version of MyLibrary with Keith Morgan and Doris Sigl. This turn-key application mimicked things like My Netscape. My Yahoo, and My DejaNews. Enter a username and password. Tell the application a bit about yourself. Be presented with content designed for you. Libraries have content. Why not do the same thing for library patrons? The process worked. It became popular, and now MyLibrary is seemingly a part of the library vernacular. By this time the term "open source" had been coined, and I was asked to sign a legal agreement with the University making the content distributable via the GNU Public License.
I out grew the NC State Libraries too and in 2001 I moved on to be more of an administrator and less of a hacker at the University of Notre Dame. There, working with Tom Lehman, Rob Fox, and Elaine Savely, we transformed MyLibrary from a turnkey application into a set of object-oriented Perl modules. In the end we implemented the same turnkey application but with a more powerful foundation. Immediately the popularity of MyLibrary plummeted. There were too few people in libraries who could write applications against Perl modules. The profession needed a turnkey system. Oh well.
Which brings me to the present day. I still write a lot computer programs, but more for my personal use than for work. For the most part I build on other people's successes and use their tools to manipulate content. Think MySQL, a raft of indexers, bunches o' Perl modules, XML processors, etc. I use these things to harvest content from the Web and extract its metadata. I write various types of XML readers and writers such as the one use to publish all of my writings and make them available via TEI, PDF, XHTML, RSS, and OAI. I am working ways to transform my writings into ePub files. Indexing as been one of my passions, and a nod goes to Roy Tennant. "Librarians like to search. Everybody else likes to find." My Alex Catalogue of Electronic Texts has been a labor of love for more than fifteen years -- a personal public library. Now-a-days I'm into digital humanities computing, but I will describe that in more detail below.
Open source software
I owe much of my experience to Dan Chudnov. I believe he, more than anybody else, spearheaded the idea of open source software in libraries with his OSS4Lib mailing list. I remember him telling stories where Richard Stallman was on one side of him and Eric Raymond was on the other side. Apparently they argued back and forth about the meaning of free, open, and the why's of software distribution. I wish I had been there too.
As you know, the definition of "free" in the context of open source software should be equated with liberty and not necessarily gratis. It really is about the licensed rights to run, modify, and redistribute a computer program's source code. These are the philosophic foundations of open source software, and I believe they are similar to the principles of librarianship. Just as the library profession does not make judgements on how content is used, open source software distributions do not limit how its output is used either.
At the same time, open source software is only as "free as a free kitten." There are financial costs associated with it. Sure, you can take the "free" kitten home, but as soon as you do you buy it a collar, cat food, and toys. A "free" kitten also costs you emotionally because you invest your heart in it while it plays with a ball of yarn, purrs lovingly, escapes out of the house over night, and returns home the next morning. Open source software has similar costs. It requires hardware to run on, and people to maintain it. It does pretty cool and tricky things, but it also breaks and can be buggy. All of these things are true for "closed" source software as well, but with open source software you can try before you buy. If there are surprises in regards to how it works, then it is your own fault for noticing them in the first place. Open source software provides you with greater freedom. This freedom comes at the price of greater responsibility, but with this responsibility also comes greater control. Do you want to dictate how your computer environment works, or do you want to be dictated by your computer environment? The choice is yours.
Just as importantly, open source software is about community. While some of its roots may be bound to the ideas of a "gift culture", its branches are supported by a community of hackers. Open source software does not thrive without community support -- sets of like-minded people who band together to solve common computing problems. They are people who realize they have more things in common than differences. They realize that if each of them contributes something then the whole will benefit. Creating and maintaining open source software is a lot like making "stone soup". One person brings the cooking pot. Another brings the water. Another brings the wood and starts the fire. Others bring carrots, potatoes, left-overs, and seasonings. In the end everybody brought a little something but get a whole lot in return. Cooperation and an appreciation for the different types of skills each person has to offer make open source software work.
In many ways building an open source software community and providing technical support is more difficult than actually writing code. There are so many issues to be addressed that have no hard-and-fast answers. What sorts of governance will be put into place? Will decisions be made through voting? Is the community a true democracy or more like a republic? Will a benevolent dictator make decisions or will direction be provided through people who have demonstrated meritocracy? How will support be provided and to what degree? IRC channels? Mailing lists? Telephone call centers? How will the financial costs associated with these services be paid? Subscriptions? Grants? Memberships? Remember, open source software is as "free as a free" kitten. There are financial obligations to be considered.
Not a panacea
Open source software is not a panacea; one must be cognizant of open source software's strengths, weaknesses, opportunities, and threats.
Strengths
Open source software benefits from the numbers game. There are six billion people in the world. More than half of them have access to the Internet. When you understand that you have more things in common with your fellow humans than differences, then it is not difficult to understand there are going to be people who have your same interests. For example, yes, there are other people who collect water. The Internet makes it easy to get in contact with these other people. Once this happens it is easy to form communities, and once communities are formed real progress can be made. I believe there is an apropos African proverb here. "If you want to go someplace quickly, then go alone. If you want to go far, then take your friends."
When it comes to open source software, there is usually plenty of choice. Do you know how many library catalog-like applications exist on SourceForge? Many people are having the same problems you are having. They try to come up with solutions and share them with others. This creates a full "marketplace" where a Darwinian sort of "natural selection" is going on. Of all the integrated library, open source software systems available, only two really cut the mustard -- Koha and Evergreen. The others certainly work and satisfy different needs, but it is unlikely they will continue to be developed and grow.
Weaknesses
Probably the biggest weakness of open source software is support. The people who write the software are not necessarily the best people to provide help against it. While they know the most about how it works, they are often times too close to the situation to be able to see the bigger picture. What seems obvious to them is not necessarily obvious to everybody else. Put another way, there is quite likely a communication gap between developers and users. The two sets of people use different vocabularies to describe the same things.
Specialized skills are needed to create and maintain open source software. We are not all auto mechanics but we all drive cars. All of us to not know who to set up and configure an Internet connection on a computer intended to be a Web server, but we all share content via HTTP. A core set of computer skills are needed to exploit hardware and software. But there is not enough time for everybody to learn these skills and learn the skills needed for other aspects of life. Choices need to be made. Resources need to be allocated. Different parts of the human condition need to be tended. Things are in a limited supply. Low-level computer expertise is one of them.
Almost by definition, institutions move slowly. As a group, us humans do not make decisions quickly, and when we do the changes are manifested over long periods of time. Change makes many people nervous. Open source software is very dynamic. It is always developing. "Software is never done. If it were, then it would be called hardware." This goes against the idea of stability. People see software for what it is -- a means to an end -- and sometimes this means is seen as an impediment as opposed to enabler. More often than not, open source software is not associated with any institution. How can such a thing be supportable if there is no one to support it? The lack of a visible institution make people uncomfortable.
Opportunities
Open source software offers so many opportunities it is difficult for me to count them all. Many of them have their roots in the low barrier to entry. Computers are everywhere and they are inexpensive. It is not hard to buy a computer for a few hundred dollars and have it equipped with more disk space than you can easily fill, and now-a-days it doesn't really matter what type of microprocessor it has let alone keyboard and monitor. Open source software makes it inexpensive to run the computer from its operating system to its word processor to its image rendering application. Granted, it might be expensive to put the computer on the Internet, but everything else is relatively cheap.
A computer is a tool and similar to an unshaped hunk of clay. What a person does with it is only limited by one's time, imagination, and ability to think systematically. The use of a computer is a strictly logical process. It does nothing that it isn't told to do. Sometimes it may seem as if it is going haywire, but in reality, somebody somewhere gave it fallible instructions and the computer runs amuck. To write software for a computer, one must be able to think systematically. Assign a variable a value. Manipulate that value through functions. Combine the value with other values. Iterate over many values. Output the result. Computer programming is much like any other set of instructions. Playing music from fake book or score. Cooking a recipe. Traveling from point A to point B through the use of a map. The music, the food, and the map are simply guidelines -- suggested outlines, routes, or plans. They can be adapted for multiple purposes. You are only limited by your ability to solve problems using the vocabulary of the tool.
Threats
Open source software is threatened by established institutions. This is not unexpected. The established institutions are made up of humans too. They are challenged by the new environment. They too need to figure out how to adapt to change. One reaction is the spread of fear, uncertainty, and doubt (FUD). People are easily swayed by such things. Praise needs to occur many times before it is taken to heart. People listen to criticism readily. Praise does not change their lives as quickly and changes in the environment. The establishment will articulate all sorts of flaws with all things new, and people will pay attention. While the establishment does not sit down to write FUD, it comes across negatively and it has an immediate impact.
The library profession's past experience works against the adoption open source software. Our profession is graying rapidly. The administrators of today -- the resource allocators -- were the people in the trenches during time of "homegrown" library systems. Those systems failed or evolved into commercial applications. For one reason or another they were seen as too expensive and unsupportable. "We've been down the road once before. Let's learn from experience", they say. "Computers are not a library's core business", say others. "We are about books", they seem to say. Again, this is based on past experience. People's perceptions are difficult to change, and when they do, the changes happens over relatively long periods of time.
Again, open source software is not a panacea. It will exist side-by-side with commercial "closed source" software. Each serves a different need for different people and instituions.
"Next generation" library catalogs
The next big challenge for library-related software, whether it be open source or not, is to figure out how to make content more useful. Find is not the problem that needs to be solved. Instead, the problem to solve is figuring out ways to do things with the information a person identifies as interesting -- services against texts.
Library catalogs are and have been essentially inventory lists -- descriptions of the things a library owns, or more recently licenses. The profession has finally gotten its head around the fact that complicated Boolean queries applied against highly structured relational database fields are not the way to go when it comes to search. Instead, we are coming around to learning that indexing technologies, complete with their simple search syntax and relevancy ranking algorithms, return more meaningful results and are easier to use. Unfortunately, we came to this understanding more than twenty years too late. Consequently, people do not think of libraries when it comes to finding information. They think of Google. Our focus was too narrow, and we did not spend enough time and energy learning how to exploit computers. We automated existing processes when we should have been more actively participating in the work of the information retrieval (IR) community.
To date, probably the most significant achievement from the IR community has been the development of "relevancy ranking" algorithms used to sort search results based on statistical significance. While there exist any number of such algorithms, probably the most often used is called Term-Frequency Inverse Document Frequency (TFIDF). This simple mathematical formula helps overcome one of the most problematic issues of Boolean queries. Suppose the perfect Boolean query was executed against a database. Suppose the results returned one hundred items. Which of these items ought you spend your time reading? The newest one? The oldest one? The first one when the list is sorted alphabetically by title? The answers to any of these questions is arbitrary if you want to read the item that best represents the query or information need.
TFIDF applies statistical analysis against an index to return results in a relevancy ranked order. The calculation of a basic TFIDF score is simple:
score = ( C / T ) * log( D / F )
where:
- C is the number of times a given word appears in a document
- T is the total number of words in a document
- D is the total number of documents in a corpus
- F is the total number of documents containing a given word
In other words, term-frequency ( C / T ) takes into account the number of times a word appears in a document compared to the document's size. Inverse document frequency ( log( D / F ) ) takes into account the number of documents in a corpus compared to the number of times the word appears in those documents. The quotient of these two sub-scores gives a "relevancy ranking".
An simple example is in order. Suppose you have a corpus of one hundred documents. Suppose you search for the word "cat" and every document contains the query term. Which document are you going to want to read? Using TFIDF you could calculate the number of times the word "cat" appears in each of your documents compared to the lengths of the documents and sort the list by that number. Presumably, the document that contains the word "cat" more often is more likely to be the document of greatest interest.
Like a basic bread recipe or a county blues song, there are a million variations on the calculation of a relevancy ranking score. Google made its billions on such a variation, specifically, weighing documents not only on word counts but also on the number of times people linked to documents -- an early form of computerized social networking.
With the increasing availability of full text content, it is time to go beyond find and access. It is time to move towards use and analysis. Ask yourself, once you acquire an item of interest what do you do with it? The answers can all be expressed with all manner of action verbs. Examples include but are not limited to: read, print, summarize, annotate, review, rank, compare & contrast, save, delete, search within, translate, trace idea, trace author, trace citation, etc.
For more almost 600 years, the bulk of information has been manifested as printed words on paper. As such it has a set of particular advantages. Portability. Longevity. Immutability. Durability. With the advent of computers, this same information can be manifested digitally with a different set of advantages. Clonable. Shareable. Mutable. Parsable. It is this last characteristic that has made indexing such a powerful tool. It is this last characteristics that provides the fodder for new opportunities in librarianship -- truly new library and information services.
By parsing out the words in text a person can be begin to count those words. Once things are counted they can be mathematically analyzed, and once they are analyzed new observations and perceptions can be articulated. Ultimately, this leads to broader understandings and the expansion of knowledge, and isn't this a lot of what librarianship is about? Isn't this one of the reasons libraries exist? If not, then why do us academic librarians teach information literacy skills?
Chart and graph are two more action verbs that ought to be added to the list of things readers do with texts. Using a Perl module I wrote, the following screen dump illustrates the fifty (50) most common words in Henry David Thoreau's Walden.

100 most commonly used words in Henry David Thoreau's Walden |
Such a thing is nothing new. The folks at Delicious have been doing this for years based on social bookmarking tags. They called them word clouds. Count the number of times significant words appear in a text. Select the top N words from the resulting list. Display the words while scaling each one in proportion to the number of times they occur. Wordle.net probably has the most beautiful tool for creating word clouds, and below is an example, again, based on Walden. Notice how the words above and the words below appear in both illustrations.
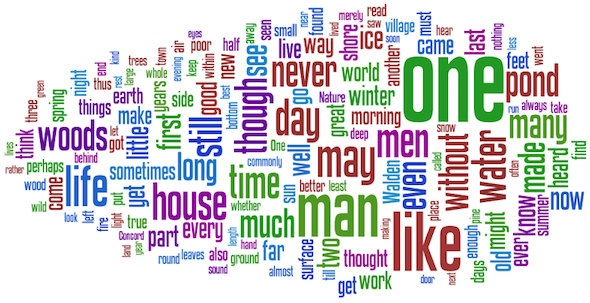
Wordle word cloud of Henry David Thoreau's Walden |
Word clouds give a person a pretty good understanding of what a text is "about" simply by counting word. As another example, here word cloud representing this essay. It should include no surprises.

Wordle word cloud of this essay |
If single word carries some meaning, then multiple words are likely to carry more meaning. Consequently, a list of the most commonly used two-word phrases may provide additional insights into the characteristics of a text, such as the following illustration, also from Walden.

50 mostly commonly used two-word phrases in Walden |
In the previous example, each of the two-word phrases are hyperlinked to the text so they can be shown in context -- a concordance -- as illustrated here.

Simple concordance of Walden |
Again, this is nothing new. Concordances have got to be one of the oldest forms of indexing, first used more than 750 years ago to analyze religious texts. With the advent of full text digital content, concordances represent a very feasible way to analyze texts. Why not provide word clouds and concordance features against the full texts in library collections?
Here is a more complicated idea, one of my own design, intended to illustrate a work's use of "great ideas". I call it the "Great Ideas Coefficient". In the 1950s Mortimer Adler and associates brought together a set "great books" for the purposes of continuing a person's liberal arts education. The result was a set of volumes called the Great Books of the Western World. Before bring the set together Adler articulated what he thought were the 100 great ideas. They included things like angel, art, courage, death, evil, god, medicine, peace, science, wisdom, world, etc. Suppose a person were to count the number of times these words appear in a document. If done, then a person could get an idea of how much a work discusses the "great ideas". If done, then such a weighting would help a person determine whether or not the work was one discussing the human condition verus instructing someone on how to grow roses. This is what I have done, and the process is not very difficult:
- create a list of "great ideas"
- compute a TFIDF score for each "great idea" in a text
- sum the scores -- the Great Ideas Coefficient -- and associate it with the text
- go to Step #2 for each document in a corpus
- search the corpus for items of interest
- compare & contrast the result based on their Coefficient score
A picture is worth a thousand words, and below is an illustration of the concept. For a number of works by Aristotle a Great Ideas Coefficient score was computed. The works were the sorted by the score and a dial-like chart was created denoting where each fell on scale from 0 to 100. Not surprisingly, Aristotle's Metaphysics ranked the highest and his History of Animals ranked the lowest.
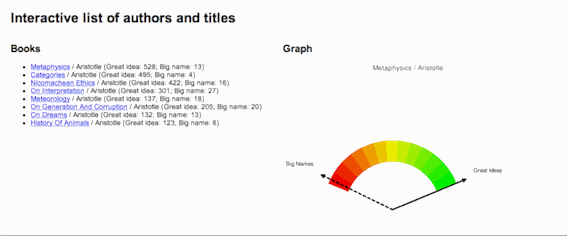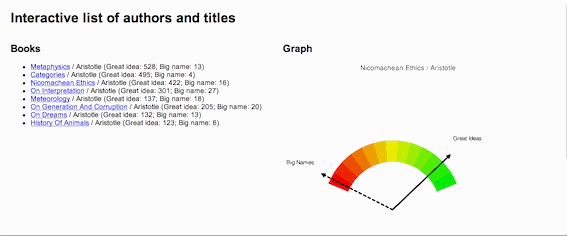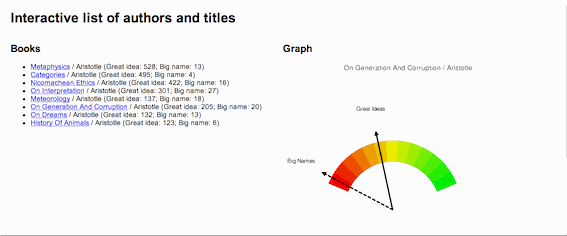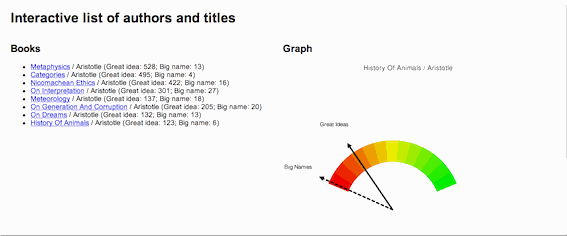
An application of the "Great Ideas Coefficient" |
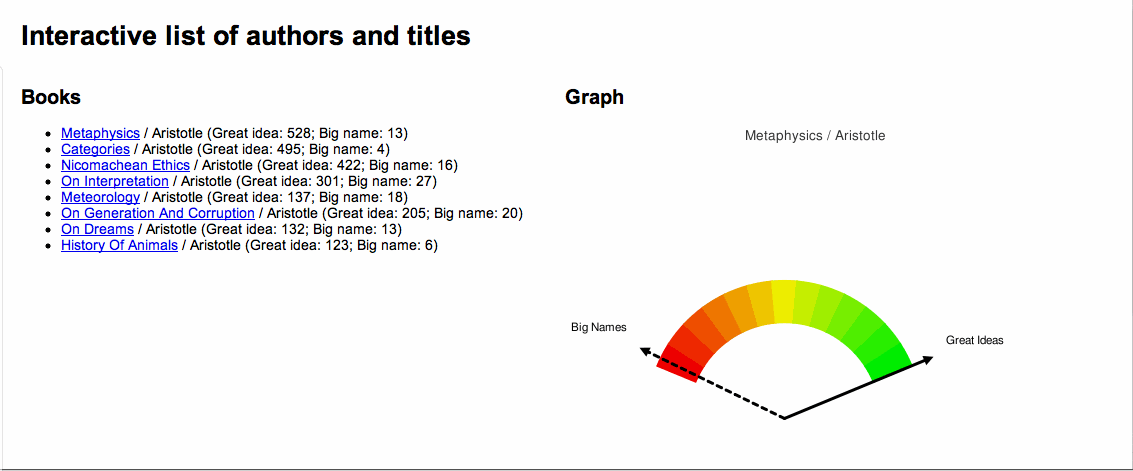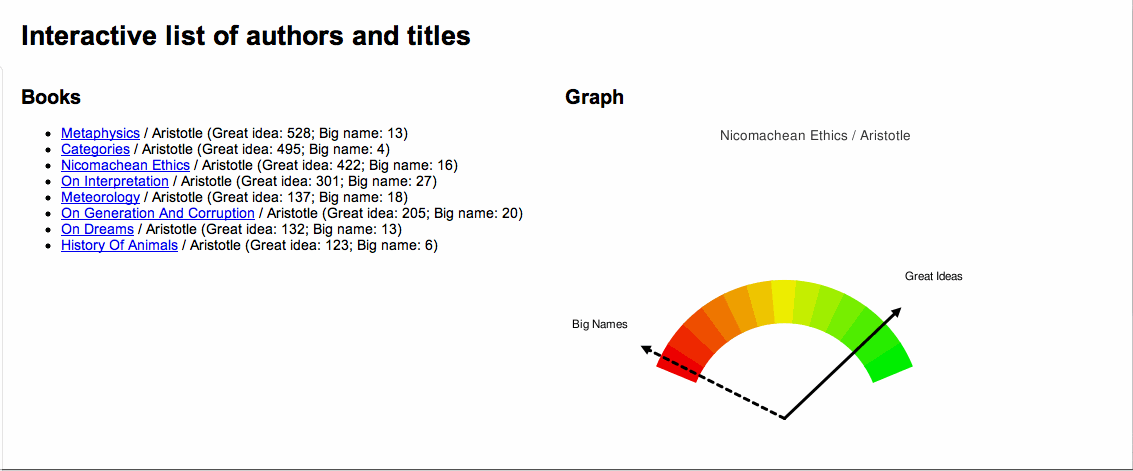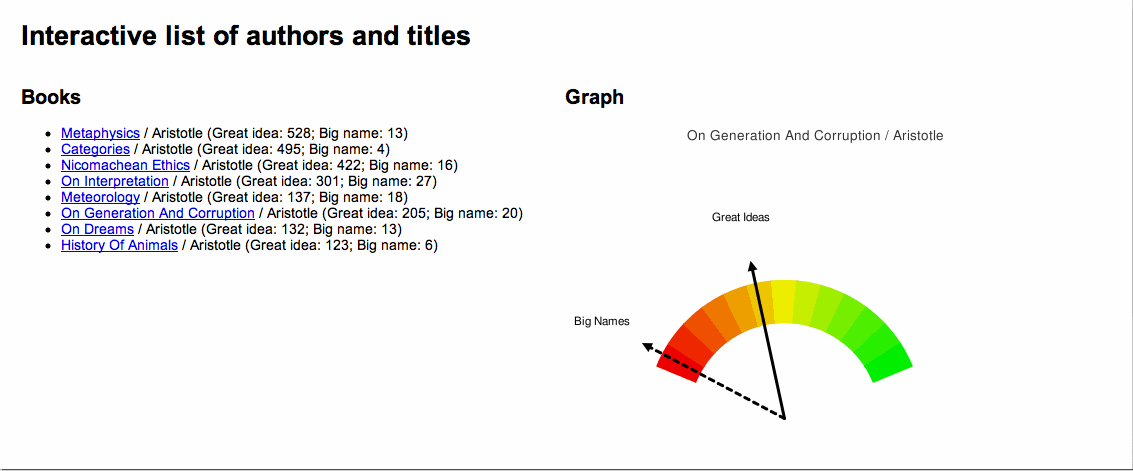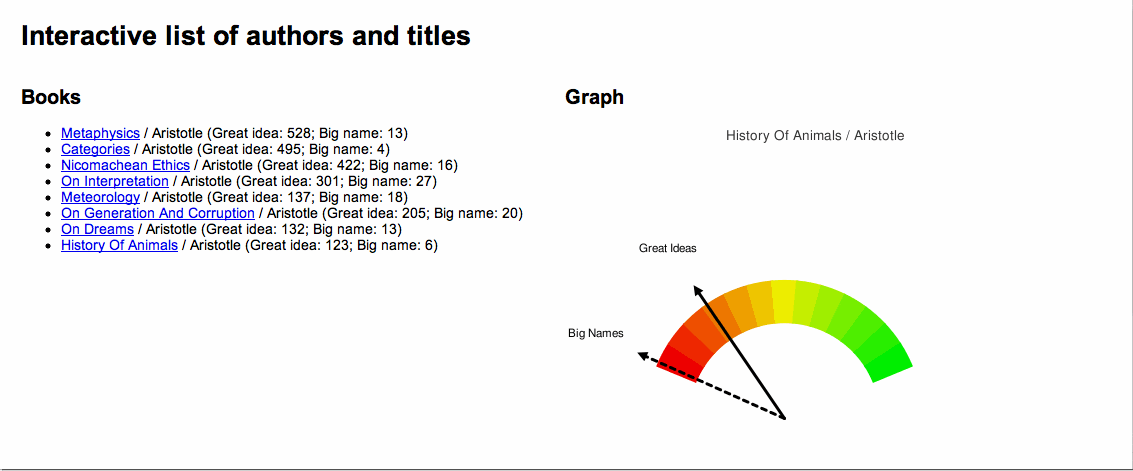{kind=link}
The same process could be applied to any other set of texts with any other set of "great ideas" -- ideas in mathematics, biology, computer science, literature, etc.
There are other ways to assign numeric scores to texts. Readability scores and grade levels are additional examples. In the early 1900s processes were being designed to determine whether or not a book's content was suitable for different readers. A book's content was evaluated on a number of qualities including but not limited to: total length in words, length of paragraphs in sentences, lengths of sentences in words, and number of syllables per word. Using the counts various types of scores can be calculated such as the intended grade level of a book (e.g. first grade, second grade, third grade, etc.) or a scale of readability measured between 0 and 100 (where 0 denotes nobody can read it and 100 denotes everybody can read it). While these processes were outlined more than 100 years ago, they can now be applied programmatically against full text content. Again, there are Perl modules supporting these tasks, and again, here is a screen shot illustrating how they have been assigned to Thoreau's Walden.

Additional quantitative metadata |
Things like a works's length, readability score, grade level, and Great Ideas Coefficient can be used as metadata describing a work, and consequently, they could be incorporated into to a search interface. Find all the works on a set of given subjects, a given length, and a readability score between a given range. The result will be a list of works. Now go beyond find to visualize and analyze the results. Plot the results on a graph. For example, sort the results according to year published. Arrange the works along the X axis of a graph. Up and down the Y axis place each work's length. Is there a relationship? In general have works with the given subjects gotten longer or shorter over time? Plot the Great Ideas Coefficient on the Y axis. Have "great ideas" played a greater or lesser role of the selected works over time? Sort the works by length and plot them them along the X axis. For the given works, is there a relationship between length and the number of "great ideas" expressed? Is it just as likely that a shorter work will contain a significant amount of "great ideas" as a longer work?
All of the above are merely examples of what can be done to do computational analysis against full text content. It works for book length items as well as article level items. It works for fiction as well as non-fiction. It works for any language of material. All a person needs is the full text of one or more works, the ability to quantify characteristics describing them, and the ability to ask meaningful questions against the results. Such is the work of the digital humanist. Such are the things of "next generation" library catalogs. Instead of mere inventory lists, "next generation" library catalogs can be tools making content useful, not just accessible.
As Mr. Ranganathan said, "Books are for use." People don't find data and information in order to just have access to it. Finding data and information is a means to an end. By providing the means for people to accomplish their ultimate goals quicker libraries will be providing their users with additional value-added services. It is time to move beyond find. Again, to quote Ranganathan, "Save the time of the reader."
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This essay was written as the closing keynote speech for the 2nd Annual Evergreen Conference (April 23, 2010), Grand Rapids (Michigan)
Date created: 2010-04-04
Date updated: 2010-04-04
Subject(s): next-generation library catalogs; presentations; open source software;
URL: http://infomotions.com/musings/oss-swot/