 "Next-Generation" Library Catalogs
"Next-Generation" Library Catalogs
This presentation outlines some of the possibilities for "next-generation" library catalogs. Specifically it describes the technology behind these applications, enumerates ways they can exploit sets of globally networked computers, and posits opportunities for new and improved services within and around them. Librarianship has traditionally been about collection, preservation, organization, and re-distribution. These over-arching goals are still relevant in today's environment, but the methods the profession can use to achieve them is changing. The venerable library catalog and the thing it seems to be morphing into is just one example. This presentation brings together the how's and why's of this issue. (This presentation is also available as one-page handout in the form of a PDF document.)
Some questions
It goes without saying that the information landscape has significantly changed with the advent of the Internet. With these changes, it behooves us to re-examine the answers to questions that we have long thought were immutable. One of these questions includes, "What is the library catalog?" To what degree is it an inventory list or a finding aide? What sorts of things is it expected to contain? What functions does it serve and for whom? More fundamentally, what sorts of problems is it expected to solve? Answering these questions, while considering the current environment, is a necessary step when it comes to designing any "next generation" library catalog application.
To my mind, the library catalog is a specialized index -- a set of pointers to information resources of particular usefulness to a library's constituents. As such, it is not necessarily an inventory list. That is only part of its functionality since the globally networked world where we live and work enables us to link and provide access to information resources that we do not own or license.
In an analog environment, information was for the most part embodied in people and a host of recorded materials ranging from cave paintings to motion pictures, from manuscripts to books, from newspapers to journal articles, from musical scores to sound recordings. In a digital environment, the types of information have taken on new forms that still include people, but also include datasets, simulations, blogs, RSS feeds, mailing list archives, Powerpoint presentations, and all of the electronic incarnations of the traditional analog materials. To what extent is the library catalog expected to contain these sorts of items? If you lean towards the inventory list side of things, then the answer to the previous question is, "Not very much." More philosophically, the answer to this question is dependent on your collection development policy which will take into account the purpose of your library, the needs of your patrons, and the resources (time, money, and skills) you are able to bring to bear. Put another way, the answers to these questions are less objective and Platonic and more down to earth and Aristotelian in nature. They can be answers in any way that makes sense for your particular institution at a particular point in time.
They're all the same
Technically speaking, the current crop of "next generation" library catalogs (Aquabrowser, Blacklight, Evergreen, eXtensible Catalog, Koha, Primo, Scribio, VuFind, etc.) have more things in common than differences.* Specifically, they all:
- normalize and distill metadata of various formats into a single information schema, and
- provide a search interface against an index of this metadata.
This is why "next generation" library catalogs are increasingly called "discovery" systems. Think index. Think search. Think find. Discovery.
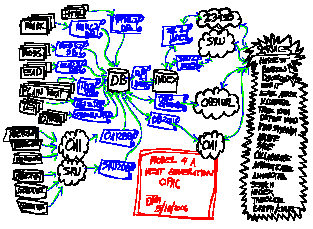
Model for a "next generation" library catalog |
{kind=link}
In most of these "catalogs", content, usually in the form of MARC data, is first saved to a centralized store -- a relational database. Next, reports are then written against the database and fed to an indexer -- increasingly an open source indexer called Lucene. Finally, some sort of user interface is provided facilitating search, browse, and navigation through the index thus enabling people to identify items of interest. The only significant technical difference between all of these applications are the interfaces provided at either end of the process -- the creation/ingestion of the metadata and its subsequent searching.
When looked at from this point of view, the changes we are experiencing in regards to "next generation" library catalogs is definitely incremental or evolutionary, not revolutionary. For the most part, the content of our catalogs is the same -- bibliographic data. Technically, we are trading the rather top-down approach of searching relational databases for the more statistical approach of searching indexes. Add a few Web 2.0 thingees -- tags, reviews, ratings, RSS syndication, faceted browse, citation creation, cover art, "your" page, a mobile interface, etc. -- and you get a "next generation" library catalog. Personally, I don't think this goes nearly far enough.
More questions
Take another step back and ask yourself about the primary activities of librarianship. Think fundamentally, and I believe we could distill the activities down to roughly four categories, each being no more important than the others: collection, organization, preservation, and dissemination. First, we bring together collections of "stuff". Traditionally, this stuff includes books and journals along with the myriad of other analog materials alluded to above. More recently, we spend more and more time and money bringing licensed content into our "collections" -- stuff we don't own but pay for the privilege of just viewing. With the advent of globally networked computers, why could this content not also be the full text electronic books and journal articles, JPEG images, streaming movies, blog postings, names and addresses of people, mailing list archives, datasets, Powerpoint presentations, etc. whether they be free or licensed?
Bringing all of these materials together into a central collection is nice, but how is anybody going to be able to access the materials if it is not organized to smaller, more manageable piles. How will they be able to access it if someone does not make the content easily available via the user's networked computer? This is what the acquisitions and cataloging processes are all about. There is a lot of scholarly material available on the Web, just for taking. Use any number of Web spiders, crawlers, harvesters, and robots to copy things locally. Is the Acquisitions Department synonymous with the Purchasing Department? Increasingly, since the Library of Congress initiated the process early in the last century, we rely on shared cataloging practices to accomplish the goal of organization. Think catalog cards, MARC records, OCLC, and authority lists (name, title, and subject). In the current environment, do these processes make the most sense? To what degree are things like XML, folksonomies, and statistical analysis more economical considering the quantities of accessible materials, especially if full text is so abundant?
The preservationists and conservators, in my opinion, probably have the most challenging library job considering the current environment. Content that is "born digital" is extraordinarily fragile and dependent on complex machinery to render it. The current best practices for digital preservation steer towards emulation or migration, and both are fraught with difficulties. In the end, we might discover that preservation is best met by the active copying of files into the future. The things that are most wanted will be those things copied forward by users, and the things that aren't are left behind to go to Big Byte Heaven.
When it comes to dissemination we think of public services -- mostly reference. Unfortunately, people don't ask nearly as many reference questions at the reference as they did in years past. The "simple" answers can be found on the 'Net. Yet there is still a need for the traditional reference interview process and the teaching of information literacy skills. How much of these things can be done at the point-of-need through a networked computer? Online chat? Intelligent interfaces to our "discovery" systems? Make the computer interfaces to our collections "smarter" by embedding our expertise into them. Create "affinity strings" outlining the characteristics of patrons and recommending information resources more tailored to specific user groups. Understand what classes a person is taking and suggest one set of resources over another.
The "Next 'next generation' library catalog"
"Discovery" is not the problem that needs to be solved. People can find more information than they have ever been able to find before. We are still drinking from the proverbial fire hose. What is needed are tools to enable people to use, to integrate, to exploit, to understand the things they find. We spend too much time worrying how to provide services against the index (Find More Like This One, Did You Mean?, faceted browse, etc.). Google does that all too well. Instead we ought to focus on providing services against the things they find (books, articles, images, scores, datasets, etc.). Compare & contrast. Make slideshow. Trace an idea through. Summarize. Annotate. Plot on a map. Graph a chat. Do word counts against. Print & bind. Play. Save. Transform. Translate. Find in a library. In my opinion, this is where the growth lies. Let Google do what it does best. Let libraries do what they have always wanted to do -- collect, preserve, organize and provide access to content for the betterment of a it's patrons.
Wouldn't it be nice if your library users said, "Not only can I find all the materials I need in my library, but it also provides me with interfaces -- people and tools -- to help me understand the things I find more quickly and easily. That library saves me time. It is well-worth the cost."
Note
* Actually, we ought to distinguish between "next generation" library catalogs, "integrated library systems", and "OPAC's". In my mind, integrated library systems represent a suite of software used to automate many library functions: acquisitions, cataloging, circulation, etc. The OPAC -- online public access catalog -- has traditionally been one of those functions in an integrated library system. The phrase "'next generation' library catalogs" is an unfortunate one, and I have always, more or less, equated it the term OPAC. In this way, systems such as Koha and Evergreen are more akin to integrated library systems but they requires some sort of "OPAC" interface.
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This presentation was written to be given at the libraries of the Purdue University on March 27 as well as an IOLUG meeting on May 15, 2009
Date created: 2009-03-25
Date updated: 2010-05-01
Subject(s): Purdue University; next generation library catalogs; Indiana On-Line User's Group (IOLUG); presentations; librarianship;
URL: http://infomotions.com/musings/ngc4purdue/