 Evaluating Index Morganagus
Evaluating Index Morganagus
Abstract
This article describes Index Morganagus, a full-text index of library-related electronic serials. First, it describes why the Index was created. It goes on to give an overview of Harvest, the technology that collects, indexes, and provides access to the serials. The article outlines how the process was automated using the combination of a database application (FileMaker Pro) and various "glue" scripts (both AppleScript and Perl). It provides an analysis of the service's log files shedding light on usage patterns and librarian search behavior.
While the Index may not be satisfying a large need in the library profession, it demonstrates the feasibility of creating similar indexes for other professions where there may be greater need. It also demonstrates how computer technology can empower librarians and provide better, in-house developed solutions and expand the horizon of library services. [1]
Why the Index was created
Index Morganagus is/was a full-text index of fifty-one library-related electronic serials available at <URL: http://sunsite.berkeley.edu/~emorgan/morganagus/ > (See Appendix A for a complete list of the indexed titles and their associated URLs.)
The purpose of the Index is/was to explore methods of collecting and providing access to freely available electronic serials and organizing them into some sort of meaningful scheme. Electronic serials, as produced by scholars themselves and not for-profit publishers, have had a number of implementation problems since their inception early this decade. These problems have included but are not limited to meager resources (time, money, and personnel), distribution, long-term maintenance, and user accessibility. A few scholarly electronic serials have overcome some of these problems, but it seems the majority of titles fail.
Early on, when most of the electronic serials were distributed via email, the North Carolina State University Libraries in Raleigh, North Carolina, USA, developed a systematic process of collecting, organizing, archiving, indexing, and disseminating electronic serials. It is called the Mr. Serials Process. [2] Its purpose is to aid in the scholarly communications process by providing traditional library services for serials, thus increasing the probability of the serials' success and longevity. Summarizing, Mr. Serials Process works as long as two conditions are true. First, the serials are delivered via email, and second, the texts are consistently formatted. In the years following the original development of the Mr. Serials Process, more and more electronic serials were being disseminated through World Wide Web servers instead of email. Thus, the Process is breaking down.
In an effort of pick up where the Mr. Serials Process left off, Index Morganagus was created. The Index collects, organizes, indexes, and disseminates but not archives electronic serials. At the expense of truly archiving any materials, the Index is a much simpler system than the Mr. Serials Process. The Index is an attempt to justify scholarly publishing by scholars by providing library services for the publications. Put another way, the Index is attempting to demonstrate that if scholars freely publish their materials electronically, then librarians can effectively provide information services against those publications. The Index was constructed and maintained using Harvest and a database program called FileMaker Pro.
Harvest
Harvest is a system of Perl, Bourne shell, and C programs. [3] It is an indexing/searching technology developed as a part of Federally funded grant at the University of Colorado, Boulder, Colorado, USA. It is made up of two parts: "gatherers" and "brokers." Given one or more URLs, a Harvest gatherer can traverse Unix file systems, gopherspaces, FTP sites, and HTTP servers. Data from these services is collected and distilled into files of the Summary Object Interchange Format (SOIF). SOIF files are ASCII text files made up of attribute-value pairs much like database fields and corresponding content. Gatherers serve their data to brokers much the same way World Wide Web browsers retrieve HTML pages from HTTP servers. Brokers are designed to regularly collect data from one or more gatherers and index that data. The data can be indexed using either WAIS or Glimpse as the indexer/search engine. (The Index uses Glimpse.) Consequently, the Harvest system, depending on which indexer is used, ultimately provides field searching, Boolean logic, nesting, regular expressions, and right-hand truncation search features against sets of Internet-accessible documents.
Harvest was designed as a distributed indexing/searching system. Ideally, every Unix-based information system (FTP, file system, gopherspace, Usenet newsgroup, or HTTP server) would have an associated gatherer database or databases. At the same time, there would be multiple brokers, all over the world, indexing combinations of gatherer databases and providing access to their content. Thus, using the Harvest system, multiple, customized search interfaces could be created providing access to world-wide collections of documents with a minimum of overhead and network bandwidth. Furthermore, the search mechanisms would be consistent from database to database.
The Harvest system works. It does what the documentation says it can do. The creation of Harvest gatherers and brokers is relatively straight forward, but the updating of Harvest gatherers can be tedious. This short-coming led to the creation of a system of FileMaker Pro databases for Index Morganagus, described in the next section.
The Glimpse system of indexing, the default and more full-featured search engine subsystem, provides less than intuitive output. This is another short-coming of Harvest. The computer adage "Garbage In, Garbage Out" applies here. Specifically, when Harvest gathers content it first determines the type of data being collected: HTML files, text files, GIF images, etc. If the remote documents are HTML files, then the contents of the <TITLE></TITLE> tags are used as a "description" of the document. On the other hand, if the file is of an unknown type or a simple text file, then a file name or the first non-blank line of the file is used as a description. Consequently, well structured HTML documents are described very well. Poorly formatted HTML documents return less than useful output. On the other hand, text files whose first line contains a human readable citation (like the ones created by the Mr. Serials Process) index very well. Others do not.
For example, a search for "NREN" in Index Morganagus returns some less than useful output since the first line of some PACS Review articles are text files where the first line is similar to "+ Page 4 +", not useful information. The problem is compounded with the creation of Harvest brokers made up of other brokers. In this scenario, all the description information is lost and defaults to the indexed file's name making the output consistently difficult to evaluate for relevance.
FileMaker Pro
FileMaker Pro is a cross-platform, relational database program sold by Claris. Using this software, a system of files was created to manage the Harvest configuration files. The system includes a database of serial titles, gatherers, and brokers. The serial titles database contains fields for titles, URLs, "filter" statements, and holding statements. The gatherer database includes fields for TCP/IP port numbers, long and short names for the gatherers, URLs of systems to be traversed, and local information like the email address of the gatherer administrator. The broker database contains fields for many of the same fields as above plus a password for broker maintenance. Since FileMaker Pro is a relational database program, data saved in one field in one database and be directly linked to other fields in other databases.
Because Harvest is designed to run on Unix computers, and since one of the ultimate goals of the Index Morganagus system was the creation of multiple indexes of electronic serials, then any system that was created had to buffer librarians from Unix. This is why a set of AppleScript scripts were written for the purposes of creating reports against these FileMaker Pro databases. These reports are really Perl scripts. Ideally, library collection managers would maintain lists of electronic serials within the FileMaker Pro serial titles database. Using pop-up menus these serial titles can be linked to the FileMaker Pro gatherer and broker databases. Next, canned reports can be generated from the databases and FTP'ed to the Unix computer hosting the gatherer and broker systems. Finally, the reports (Perl scripts) can be executed resulting in the maintenance of the entire Index. In short, the system is designed in such a way that a librarian simply keeps track of electronic serials, clicks a few buttons, and creates a full-text index of academic titles.
Implementation
Implementation began in the late summer of 1996 on a Digital Equipment OSF/1 computer with less than 4 GB of hard disk space and 32 MB of RAM. Roy Tenant, manager of the University of California-Berkeley SunSITE, kindly offered to provide server space for the Index and further explorations took place there. Consequently the Index now runs on a Sun Solaris computer with 112 GB of hard disk space and 1 GB of RAM. Of course, the Index does not require 112 GB of disk space. In fact, the Index only requires 114 MB which includes configuration files, gatherer databases, broker indexes, HTML files describing the system, and log files.
Once the original setup was complete, maintenance of the service was rather trivial. Unix cron jobs were written for the purposes of refreshing the gatherer database(s) every two weeks. Other cron jobs were written to extract, rotate, and analyze log files. Whenever new library-related electronic serials were discovered, they were evaluated, and if deemed appropriate, they were added to the Index's configuration files.
The Index was announced the last week of December 1996. In its original implementation, the Index really consisted of three indexes. One was an index of peer-reviewed titles. One was an index of non-peer reviewed titles. The third was a combination of the first two indexes. Based on usage logs, it was evident the third index was the most popular and given the output problems of combining multiple broker indexes (described above), the first two indexes were combined into one gatherer database making searches against the entire collection much more readable.
Additionally, since the browsability of any information system is beneficial, soon after the Index's inception a pop-up menu of all the titles in the Index was included on the service's home page. This allowed users of the service to not only search the collection but navigate directly to any serial title in question.
Log file analysis
From January 1 to July 31, 1997, the entire set of Index Morganagus pages serviced 23,189 hits or an average of 110 requests per day. Figure 1 illustrates how these requests were distributed through this time period.
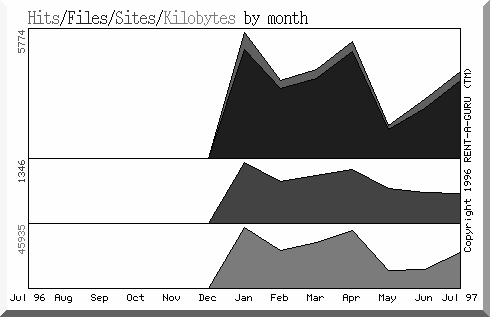
Figure 1. Hits per month from January 1 to July 31, 1997 |
After an analysis of each month's of activity, June 1997 represented a average snapshot of activity. Figure 2 illustrates the usage of the Index for every day in June. As expected, usage is consistent from weekday to weekday with drops in service on the weekends.
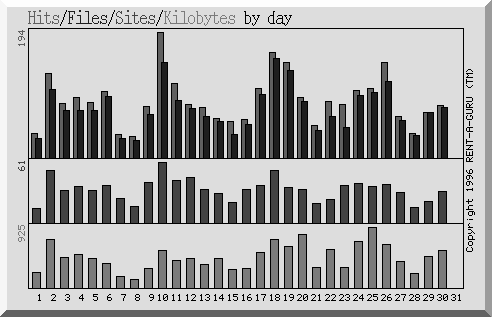
Figure 2. Requests in the month of June 1997 |
Again, as expected, the service was used more heavily during the noon hour as illustrated by Figure 3.
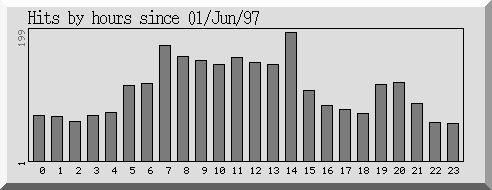
Figure 3. Requests during times of day |
Figure 4 illustrates the service was used by quite a diverse set of domains (countries). This trend was surprising.
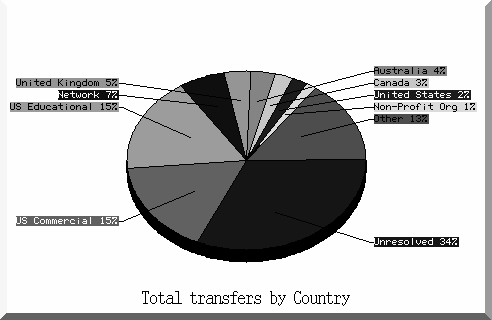
Figure 4. Domains using the Index |
Further analysis of the domains accessing the service hilighted another unexpected outcome. Specifically, the service's most popular users were Internet robots from Excite (atext.com) and AltaVista (dec.com) as Table 1, the top 20 users of the Index, illustrates. [4]
| Host | Hits |
| xxx.atext.com | 882 |
| 129.71.57.xxx | 501 |
| xxx.lib.berkeley.edu | 251 |
| xxx.bath.ac.uk | 221 |
| xxx.york.ac.uk | 166 |
| 129.71.57.xxx | 155 |
| 129.29.90.xxx | 137 |
| xxx.atext.com | 112 |
| xxx.sannet.gov | 105 |
| xxx.demon.co.uk | 96 |
| 208.16.170.xxx | 89 |
| xxx.tenet.edu | 89 |
| xxx.pa-x.dec.com | 82 |
| xxx.atext.com | 79 |
| xxx.inrialpes.fr | 74 |
| 131.162.142.xxx | 73 |
| xxx.dmu.ac.uk | 66 |
| xxx.lib.iastate.edu | 62 |
| xxx.executiveresearch.com | 57 |
| xxx.lut.ac.uk | 55 |
A complete log file analysis report is available online.
Of the 23,189 hits to the service, only 6,373 (roughly 27%) were actual searches. If the Internet spiders are removed from the total number of hits, then the total number of hits is 21,932 and the 6,373 searches represent 28% of the total. In other words, more people read the texts describing the Index rather than actually using it. This too was unexpected since one would hope the ratio of home page requests to search requests would be at least 50-50.
An analysis of the types of searches serviced was made. The Glimpse search engine provides for phrase searches, right-hand truncation, Boolean logic, compound (nested), field, and simple single-term queries. The table below illustrates how many times each of these types of searches were done. (The figures to not add up to the total number of searches since some of them can be combined into single queries.) See Table 2.
| Phrase | 1228 |
| Truncation | 288 |
| Logical AND | 3569 |
| Logical OR | 167 |
| Compound | 103 |
| Field | 55 |
| Single term | 2143 |
| Total searches | 6,373 |
Based on these figures, it is evident the users of the system did not take full advantage of its search features. Assuming librarians would be most interested in the Index, you would expect librarians to exploit the full range of search features. In reality, most people entered simple phrase queries with no punctuation. Since there was no punctuation, the system converted these queries onto Boolean union queries. Many examples can be found in the system's log file. A short list includes:
- collection AND development
- digital AND libraries
- search AND engine
- electronic AND journal
- virtual AND reality
- user AND education
- business AND case AND study AND answers
- special AND libraries
- off AND campus AND library AND service
A complete search transaction log analysis report is available online.
Survey results analysis
Since the inception of the Index, links to an online survey have been available from the Index's home page as well as search results pages. This survey was intended as a means for gathering specific answers from users of the system in the hopes of improving it. To date, only 135 surveys have been returned.
When asked, "Are you a librarian?", most respondents said yes as illustrated by Figure 5.
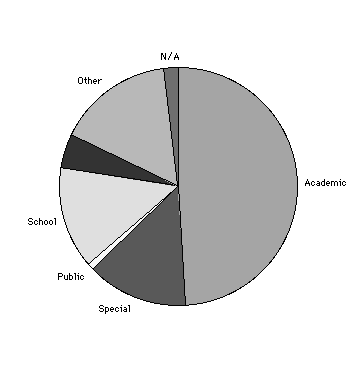
To the question "If you are a librarian, then what type of librarian are you?" most said they were academic librarians as shown in Figure 6.
When asked, "How useful did you find the Index?", most said the Index was at least "somewhat" useful. See Figure 7.
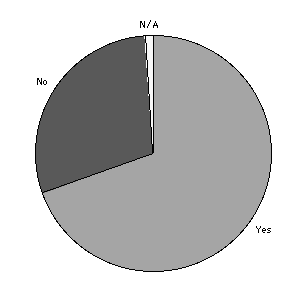
When asked, "Did your searches return the sorts of results you expected?", most answered affirmatively as illustrated in Figure 8.
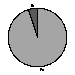
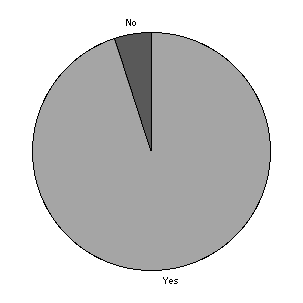
Figure 9 illustrates that most people thought the service should be continued because they answered affirmatively to "Do you think this service should continue beyond Easter 1997?"
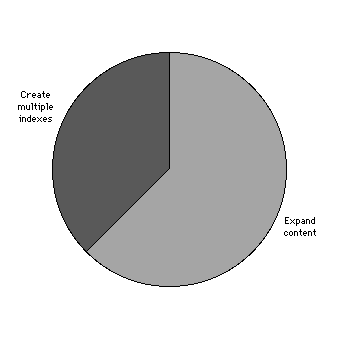
Another goal of the Index was to discover whether or not the system should be expanded to include academic disciplines/professions beyond librarianship. Consequently, the survey asked, "If you had only one choice, would you like to see the content of the Index expanded to include tables of contents, lists of OPACs and libraries, home pages of reference, acquisitions, and cataloging services, etc., or do you think multiple indexes should be created like this one specializing in other disciplines like mathematics, biology, astronomy, etc?". Most thought the service should be expanded to other disciplines as illustrated by Figure 10.
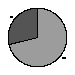
Librarian? |
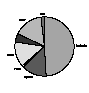
Type of librarian? |
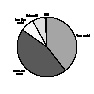
Usefulness? |
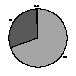
Expected results? |
Continue service? |
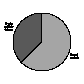
Expand content? |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The survey also included a space for people to make anonymous or public comments. This section of the survey proved to be most useful. The majority of the comments were positive expressing a desire to keep the Index in production. See Appendix B.
At the same time, many people commented on the Index's output as being too difficult to understand or poorly formatted. See Appendix C.
A complete list of all the public and anonymous comments made during the survey process are available online.
Conclusions
Based on the experience of almost 9 months use, the Index can be deemed a qualifed success. It truely does index and provide access to a large body of electronic literature and it does this with a minimum of routine maintenance.
But the Index is not without it faults. Its initial creation was not trival, but anybody with a mediocum of Unix and Internet server experience should be able to get at least an experimental Harvest server up and running in less than one day. At the same time, Index Morganagus contains links to thousands of electronic texts and the actual index creation process requires a Unix computer larger than the average desktop workstation. Access to such a machine is usually not within the easy reach of most users.
The biggest problem of Harvest lay with its user interface. For example, Harvest (Glimpse) search syntax is a bit archane. While it supports field searching, the field names are not always apparent. Furthermore, it is difficult, if not impossible, to create a search form with multiple input fields. Consequently, users must specify field searches using highly structured queries that sometimes involve the "black art" of Unix regular expressions.
The system's indexing process is not perfect. One problem brought to our attention was the poor indexing of Newsletter on Serial Pricing Issues. The conical site for this serial was being indexed by Harvest but returning incorrect search results. Why this was happening was not discovered. Instead, a different archive of the serial is being used and search results are now correct.
The system's user interface falls short when it comes to displaying the output of searches. First, the system assumes structured data will form the content of indexing. If the indexed data has little or no structure, then the system can and will not create a quality index. For HTML files, this structure includes at least TITLE and META tags. The content of TITLE tags prove useful for identifying located items. META tags prove useful for the purposes of field searching. The inclusion of these tags was more problematic early in the Index's implementation, but now more and more people are including META tags in their HTML files. The ommision of TITLE tags is all but unheard of except for the oldest of HTML files. Older sets of data, like sets of flat ASCII text files, would more likely be chosen from search results if they were marked up in HTML.
Second, by default, the system outputs search results as a cryptic array of attribute-value pairs representing fields and content. These attribute-value pairs are items in the database matching user queries. Only for the sufficticated Harvest (Glimpse) user do these attribute-value pairs make any sense. It is possible to customize the output of Harvest (Glimpse) queries, and to some extent this has been done for the Index, but the process required an indepth understanding of Glimpse and Perl. There are no insurmountable obstacles for creating effective Harvest services, but the difficulty presenting "human readable" search output comes close.
The FileMaker Pro front-end to the Index's configuration files has proved itself to be overkill. For the routine maintenance of one Harvest system, the FileMaker set of databases are unnecessary. On the other hand, if multiple indexes were to be maintained, then this system of FileMaker databases may prove to be indispensible.
Future directions and librarianship
The Harvest technology, and indexing techniques in general, provide wonderful opportunities for librarianship. Traditionally, libraries have been about collecting, organizing, archiving, and disseminating data and information. With the advent of globally networked computers, libraries can provide these same services on a much wider scale. With the availablility of indexing services like Harvest, libraries can expand the scope of their information services into realms previously occupied only by commercial vendors.
Used effectivley, the Harvest technology could provide the foundation for the creation of a freely available, full-text bibliographic index to the world's scholarly information. The first step would be for scholars to publish their findings electronically and freely. Next, libraries could create subject-based archives of these published, scholarly materials. These same libraries would then index their archives effectively creating indexes similar to Index Medicus, Biological Abstracts, Computer Index, Science and Technology Index, AGRICOLA, Library Literature, etc. Since the indexes could have been created using the Harvest technology, these indexes could be combined into meta-categories like the science or humanities allowing people to search them and locate information from a wide range of electronic serials. Finally, these meta-categories could be combined to ultimately create something akin to Academic Index. The technology is there. The problem with the plan is the begining of the process, the free distrubution of electronic scholarly publications.
Index Morganagus is not an isolated library implementation of the Harvest technology. The Loca Indexes (Index Antiquus and Index Bibliothecae) hosted by the Wichita State University Libraries and the UK Engineering Search Engine hosted by the Edinburgh Engineering Virtual Library are two cases in point. They ould be combined with Index Morganagus and begin the creation of a global index. [5, 6]
Another possibility is the creation of rudimentary expert systems for the purposes of assisting users in using Harvest services. For example, a program could be written >similating the reference interview. The system would ask users questions like:
- What do you want to know?
- What do you want to know about X?
- If you were to find the "perfect" article on X, then what would it's title be?
- Do you know of any authors who have written about X, and if so, what are their names?
- Do you know the titles of any articles about X, and if so, what are those title?
Based on the answers to these sorts of questions, sophisticated Harvest (Yahoo, AltaVista, Excite, etc.) searches could be created and issued on behalf of the user hopefully creating more exact search results and improving precision/recall ratios.
Computer technology is an empowering technology. Harvest is a good example. While it may not be perfect it represents a tool librarians can use to improve library services instead of simply automating them.
Notes
- A complete, prepublished text and links to more detailed information listed in this article can be found at <URL: http://infomotions.com/musings/morganagus/ >
- Description and Evaluation of the "Mr. Serials" Process: Automatically Collecting, Organizing, Archiving, Indexing, and Disseminating Electronic Serials, Serials Review 21 no. 4 (Winter 1995): 1-12, <URL: http://infomotions.com/musings/serials/ >.
- Harvest was originally designed at the University of Colorado, Boulder, Colorado, USA. The original location of the Harvest distribution was <URL: http://harvest.cs.colorado.edu/ >. After initial funding for the project was exhausted, the distribution was moved to <URL: http://harvest.transarc.com/ >. Since then significant improvements have been made to the software and now the most up-to-date version of the Harvest distribution can be found at <URL: http://www.tardis.ed.ac.uk/harvest/ >.
- The most specific part of the addresses listed in this table have been masked to protect the identity of the individuals using the Index.
- See <URL: http://loca.ablah.twsu.edu >.
- See <URL: http://www.eevl.ac.uk/uksearch.html >.
Appendix A
This is a list of the indexed serial titles, URLs, and "holdings".
| ACQNET | <URL:http://www.lib.ncsu.edu/stacks/a/acqnet/> | vol 1 - (Dec 10, 1990 - ) |
| Action for Libraries | <URL:http://www.bcr.org/~shoffhin/> | vol. XXII, no. 11 - (Nov 1996 -) |
| ALA News Releases | <URL:http://www.lib.ncsu.edu/stacks/a/alareleases/> | (Jun 2, 1995 - Sep 20, 1995) |
| ALA News | <URL:http://www.lib.ncsu.edu/stacks/a/alanews/> | (Jan 11, 1994 - Feb 2, 1996) |
| ALAWON | <URL:http://www.lib.ncsu.edu/stacks/a/alawon/> | vol 1, no 1 - (Dec 18, 1992 - ) |
| ALCTS Network News | <URL:http://www.lib.ncsu.edu/stacks/a/ann/> | vol 1, no 1 - (May 13, 1991 - ) |
| Ariadne | <URL:http://www.ariadne.ac.uk/> | no. 1 - (Jan. 1996 - ) |
| ARL Newsletter | <URL:http://arl.cni.org/newsltr/newsltr.html> | no. 184 - (Feb 1996 - ) |
| ASIS Bulletin | <URL:http://www.asis.org/Bulletin/> | vol. 21, no. 2 - (Dec/Jan 1995 - ) |
| Automatome | <URL:http://www.lclark.edu/~lawlib/automatome/> | vol. 14, no. 3 - (Summer 1996 - ) |
| Bulletin des Bibliotheques de France | <URL:http://www.enssib.fr/Enssib/bbf/bbfeng.html> | no. 5 - ([Oct?] 1995 - ) |
| Chinese Librarianship | <URL:http://www.lib.siu.edu/swen/iclc/clej.htm> | no. 1 - (June 1, 1996 - ) |
| Citations for Serial Literature | <URL:http://www.readmore.com/info/csl.html> | vol 1, no 1 - (Feb 20, 1992 - ) |
| Commission on Preservation and Access Newsletter | <URL:http://palimpsest.stanford.edu/cpa/newsletter/cpanl.html> | no. 1 - (June 1988 - ) |
| Computers in Libraries | <URL:http://www.infotoday.com/cilmag/ciltop.htm> | vol. 16, no. 5 (May 1996 - ) |
| CONSERline | <URL:http://www.lib.ncsu.edu/stacks/c/conserline/> | no 1 - (Jan 1994 - ) |
| CTILIS Newsletter | <URL:http://info.lboro.ac.uk/departments/dils/cti/newslttr.html> | vol. 5, no. 1 - (Jan/Feb, 1994 - ) |
| Current Cites | <URL:http://sunsite.berkeley.edu/CurrentCites/> | vol 1, no 1 - (Aug 1990 - ) |
| D-Lib Magazine | <URL:http://www.dlib.org/back.html> | [no. 1?] - (Jul, 1995 - ) |
| database | <URL:http://www.onlineinc.com/database/> | vol. 18, no. 1 - (Feb 1995 - ) |
| Electronic Journal on Virtual Culture | <URL:http://www.lib.ncsu.edu/stacks/e/ejvc/> | vol 1, no 1 - (Mar 23, 1993 - ) |
| IEEE Computer Society Digital Library News | <URL:http://cimic.rutgers.edu/~ieeedln/> | vol. 1, no. 1 - (June/July 1997 - ) |
| Infobits | <URL:http://www.iat.unc.edu/infobits/infobits.html> | no 1 - (Jul 1993 - ) |
| Information Policy Online | <URL:http://www.lib.ncsu.edu/stacks/i/ipo/> | vol 1, no 1 - vol. 1, no 8 (Mar 1994 - Oct 1994) |
| Information Research | <URL:http://www.shef.ac.uk/uni/academic/I-M/is/lecturer/ircont.html> | vol1., no. 1 - (Apr 1995 - ) |
| Information Technology and Disabilities | <URL:http://www.rit.edu/~easi/itd.html> | vol 1, no 1 - vol 3, no 1 (Jan 1994 - Mar 1996) |
| Information Today | <URL:http://www.infotoday.com/it/itnew.htm> | vol. 13, issue 3 - (March 1996 - ) |
| INFOSYS | <URL:http://www.lib.ncsu.edu/stacks/i/infosys/> | vol 1, no 1 - (Jan 5, 1994 - ) |
| Internet Trend Watch for Libraries | <URL:http://www.leonline.com/itw/> | vol. 1, no. 1 - (Jun 1996 - ) |
| Irish Library News | <URL:http://www.ul.ie/Services/Library/iln.html> | no. 154 - ( Dec 1994 - ) |
| IRLIST Digest | <URL:http://www.lib.ncsu.edu/stacks/i/irld/> | no 000 - (Dec 5, 1989 - ) |
| Issues in Science and Technology Librarianship | <URL:http://www.library.ucsb.edu/istl/> | no 0 - (Dec 1991 - ) |
| Katharine Sharp Review | <URL:http://edfu.lis.uiuc.edu/review/> | no. 1 - (Summer 1995 - ) |
| LC Cataloging Newsletter | <URL:http://www.lib.ncsu.edu/stacks/l/lccn/> | vol 1, no 1 - vol 3, no 2 (Jan 1993 - Jan 1995) |
| LIBRES | <URL:http://www.lib.ncsu.edu/stacks/l/libres/> | vol 2, no 1 - (Aug 1992 - ) |
| Link-up | <URL:http://www.infotoday.com/lu/lunew.htm> | vol. 13, no. 2 (March/Apr 1996 - ) |
| LITA Newsletter | <URL:http://www.harvard.edu/litanews/> | vol. 16, no. 2 - (Spring 1995 - ) |
| LJ Digital | <URL:http://www.ljdigital.com/> | (Feb 1997 - ) |
| Marketing Library Services (MLS) | <URL:http://www.infotoday.com/mls/mls.htm> | vol. 10, no. 2 (March 1996 - ) |
| MCJournal | <URL:http://wings.buffalo.edu/publications/mcjrnl/> | vol. 1, no. 1 - (Spring 1993 - ) |
| MSRRT Newsletter | <URL:http://www.cs.unca.edu/~davidson/msrrt/> | vol. 9, no. 1 - (Feb 1996 - ) |
| Nachtrichten fuer Dokumentation | <URL:http://www.darmstadt.gmd.de/NFD/> | vol. 46, no. 5 - (Oct 1995 - ) |
| Network News | <URL:http://www.lib.ncsu.edu/stacks/n/nnews/> | no 1 - no 15 (Oct 1992 - Apr 6, 1995) |
| Newsletter for Serials Pricing Issues | <URL:http://www.lib.unc.edu/prices/> | no. 2 - (May 30, 1991 - ) |
| Olive Tree | <URL:http://timon.sir.arizona.edu/pubs/olive.html> | |
| Online Magazine | <URL:http://www.onlineinc.com/onlinemag/> | vol 19, no. 1 - (Jan 1995 - ) |
| Online User | <URL:http://www.onlineinc.com/oluser/> | vol. 1 no. 1 - (Oct/Nov 1995 - ) |
| Public Access Computer Systems News | <URL:http://www.lib.ncsu.edu/stacks/p/pacsn/> | vol. 1, no. 1 - vol. 6, no. 5 (1990 - 1995) |
| Public Access Computer Systems Review | <URL:http://info.lib.uh.edu/pacsrev.html> | vol. 1, no. 1 - (1990 - ) |
| Searcher | <URL:http://www.infotoday.com/searcher/srchrtop.htm> | vol. 4, no. 5 (May 1996 - ) |
| TER (Telecommunications Electronic Reviews) | <URL:http://www.lita.org/ter/> | vol. 1, no. 1 - (1994 - ) |
Appendix B
This is an incomplete list of survey comments recommending the Index remain active.
- "I was very pleased to find this index, and hope that it will continue" --4/10/97
- "Tried it out for my research project on consortium formation -- contains material not available through more conventional indexes. Will come back and look more thoroughly. Keep it up and thanks!" --4/9/97
- "Sir, I welcome the service you provide. As a grad. student and soon (I hope) public librarian, a tool of access for library related e-serials will be helpful. Currently, I seek information on public library programs that serve "latchkey children". For this purpose, the journals your index includes weren't useful. Maybe, I just don't see it today. I'll try again soon. Please consider keeping the site open! Thanks, jt mls'97 ?" --2/7/97
- "Great index! I had never even heard of several of the journals before, and I enjoyed browsing them. The search provided good results, but I thought the browsing was more fun. Hope you'll keep this service going for us. " --2/19/97
- "I find this an invaluable resource for quickly searching across a very wide range of LIS material - this, in some ways, is the "holy grail" of those of us who want to see what is being discussed on some LIS subject on a global basis. Please keep this service running a lot longer than Easter 1997! " --1/16/97
- "The service is definitely a step in the right direction for controlling information in electronic serials. We have linked this to the Resources page of the Information Sciences Library and find it to be very useful. I hope it is successful and continues past Easter." --1/30/97
Appendix C
This is an incomplete list of the comments recommending the Index's user-interface be improved.
- "It would be nice to have a summaries included with the hit list, as most of the wwww browsers are doing now. Preferably taken from the meta description tag, but the first paragraph or so of text would be nice too. I've noticed that a lot of Harvest-based indexes return similar results; is this a limitation of this particular technology? Is anyone working on improving it? Index Morganagus is still very useful as is because the search is limited by source, but would be improved by higher quality information on the hit list." --4/14/97
- "Just wish it was easier to tell from the results list what the return really was." --4/8/97
- "You can first give the List of Magazines and ask the user to first select the magazine(s) to search. Then ask for the query. An example of a query can also be permanently displayed on the page. Is there any possibility of selecting up to a maximum of five sentences containing the search words rank them and display as a sort of "annotation" for the user to judge the relevance of the retrieved document? Am I ask ing for too much ?" --3/5/97
- "If the Index were expanded and it would be possible to see more hits this Index would be much more useful. In it's current state I didn't find it very helpful as it truncated the search results (i.e. I only got to see 10 hits but it told me 12 were turned back because the 100 line limit was exceeded. What I saw in those 100 lines d idn't really help much." --2/25/97
- "The interface could be better designed. You don't need to waste space up front telling users what technology you're using. You could work on achieving a better convergence of basic and advanced searching options. You need to display number of items retrieved at top of page, not bottom. It is not really acceptable in an information retrieval system to present retrieved items in the form of a file name. You will need to find a way of including at least the title, to allow the user to judge the relevance of retrieved items The technical quality of the documents varies considerably. This is outside your control, but your application may be judged by this. Users are accepting, however, of varying forms of presentation, if they are alerted to this in some way - e.g., source info in citation might make it clear" --2/17/97
- "In the format of the page - you do not tell someone how many articles that they have retireved. This would be very helpful." --2/10/97
- "Great idea! However there is a major problem with this - the output of a search gives too few clues about where links are, who articles were written by, article titles, etc. This is a fundamental problem with information on Web pages. Ideally there would be an equivalent to a 'title' page on Web pages, giving 'bibliographic' information, but as yet there is no standard arrangement for such details and they may not even be in cluded at all. " --1/3/97
- "I'm low-level computer smart, so this may be something I could fix, but the lines were too wide for my monitor screen. So I was using scroll bars in two dimensions. Inconvenient. The search results were excellent though. I'm just beg inning to explore electronic journals." --12/19/96
- "I'd like to see this maintained & expanded as appropriate with other lib. journals as they appear. I think naming the index after yourself is a little, uh, much. There is a problem with the results display--should show a standard index citation (article title, journal, date. " --12/17/96
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This is a pre-edited edited copy for Eric Lease Morgan, "Evaluating Index Morganagus: indexing and providing access to library-related serials using Harveset" New Review of Information Networking. 3:223-244, 1997.
Date created: 1997-04-17
Date updated: 2005-05-07
Subject(s): indexing; articles;
URL: http://infomotions.com/musings/morganagus/