 Indexing and abstracting
Indexing and abstracting
This presentation outlines sets of alternative processes for traditional library indexing and abstracting practices. To do this it first describes the apparent goal of indexing and abstracting. It then describes how these things have traditionally been manifested. Third, it outlines how the goals of indexing and abstract can be implemented through the exploitation of computer technology. Finally, it describes some ways computers can be used even more to go beyond traditional indexing and abstracting to provide services against texts.
Traditional indexing and abstracting
As the size of any library collection grows so does need for a library collection to become searchable. This is true on the macro level as well as the micro level.
On the macro level this is easy to see. As the number of books a library owns increases so does the need for a library catalog. If a library's book collection measures in the hundreds, then finding a particular book is relatively easy, especially if there is a librarian around who knows the collection. But once the collection measures in the thousands or millions, then idly wandering up and down the stacks becomes labor intensive, even with the aid of a librarian.
The same thing holds true at the micro level. Suppose you have a handful of articles from a journal -- texts measuring maybe a dozen pages long. Finding that one article elaborating upon a particular topic oughtn't be too difficult, especially if the articles have meaningful titles and have been broken into sections with descriptive headings. Browsing the small collection should be straight-forward. Now multiply the problem by the thousands of journals published every year and the hundreds of articles in each one. The problem of finding the desired information becomes one of scale.
Traditional indexing and abstracting services provided a means to overcome these problems, especially at the micro level. Thanks to William Frederick Poole, for more than 150 years there have been librarians creating indexes and abstracts of the journal literature for the library community. Back-of-the-book indexers offer similar services, and at the risk of trivializing, the process is simple and straight-forward:
- assemble a set of subject experts
- create and maintain a set of controlled vocabulary terms
- have subject experts read content and assign vocabulary terms to the content
- have subject experts summarize content by writing a narrative description of it
- publish the result in analog or digital form
- go to Step #1
The result of such a process was an index -- a list of words (authors, titles, etc.) and associated pointers (citations or page numbers) describing where items with those words could be found. The end results was essentially a list of words and pointers, and the only difference between a journal article index and a back-of-the-book index was the lack of a controlled vocabulary in the later. Figure 1 depicts a back-of-the-book index.

Figure 1, traditional back-of-the-book index |
Traditional indexing and abstracting services serve their purposes pretty well when the original content in question is in an analog format -- printed on paper. Because paper-based items are not easily duplicated nor are they easily parsed by computers, indexing and abstracting services created surrogate access to their physically bound associates. (Yes, the puns are intended.) With the advent of computers the resulting indexes have been manifested as database applications. Think of the venerable ERIC and MEDLINE indexes pioneered by the United States government in the early 1970s. Think of the DIALOG family of indexes in the 1980s. Think of the indexes (databases) so prolific and predominately displayed throughout an academic library's website.
Even with manifestation of these indexes as database applications, they are not without problems. First of all, any controlled vocabulary is a product of human language, and human language is ever-changing and ambiguous. Therefore any application of a controlled vocabulary against a text is also ever-changing and ambiguous. The successful application of a controlled vocabulary must be thorough, rigorous, and consistent, but this thoroughness, rigor, and consistency is lost over time. Langage is ever-changing and ambiguous. In order to be successful, a shared meaning of the controlled vocabulary must be held by both the indexer as well as the reader, and this is not something that can be taken for granted. While the Boolean logic of database applications provides for a high degree of searching exactitude, the best Boolean logic search may return more content than one can actually read. To make matters even more difficult, the effecive use of databases require one to know the structure of the database -- what fields exist and what types of content can be found in them. In other words, databases require the searcher (or search engine) to specify exactly what field(s) to query and why. Finally, traditional indexes and abstracts are physically separate from their original content, and thus it is difficult to see how search terms are used in the context of the original content.
Computer-generated indexes
When content is exceedingly digital in nature, traditional indexes and abstracts fall flat when compared to other approaches to finding and using information. This became obvious to the Information Retreival (IR) community more than fifty years ago. For example, instead of selectively identifying words or phrases from a text as important index terms, why not index every word? Such an idea is not feasible for a human, but a computer can do it readily. Once a computer parses out every word in a text it can then count the number of times each word occurs. It can count the number of times each word occurs next to another word. With a computer the creation of such things is almost trivial.
To date, probably the most significant achievement from the IR community has been the development of "relevancy ranking" algorithms used to sort search results based on statistical significance. While there exist any number of such algorithms, probably the most often used one is called Term-Frequency Inverse Document Frequency (TFIDF). This simple mathematical formula helps overcome one of the most problematic issues of Boolean queries. Suppose the perfect Boolean query was executed against a database. Suppose the results returned one hundred items. Which of these items ought you spend your time reading? The newest one? The oldest one? The first one when the list is sorted alphabetically by title? The answers to any of these questions is arbitrary if you want to read the item that best represents the query or information need.
TFIDF applies statistical analysis against an index to return results in a relevancy ranked order. The calculation of a basic TFIDF score is simple:
score = ( C / T ) * log( D / F )
where:
- C = the number of times a given word appears in a document
- T = the total number of words in a document
- D = the total number of documents in a corpus
- F = the total number of documents containing a given word
In other words, term-frequency ( C / T ) takes into acount the number of times a word appears in a document compared to the document's size. Inverse document frequence ( log( D / F ) ) takes into account the number of documents in a corpus compared to the number of times the word appears in those documents. The quotient of these two sub-scores gives a "relevancy ranking".
An simple example is in order. Suppose you have a corpus of one hundred documents. Suppose you search for the word "cat" and every document contains the query term. Which document are you going to want to read? Using TFIDF you could calculate the number of times the word "cat" appears in each of your documents compared to the lengths of the documents and sort the list by that number. Presumably, the document that contains the word "cat" more often is more likely to be the document of greatest interest.
Like a basic bread recipe or a county blues song, there are a million variations on the calculation of a relevancy ranking score. Google made its billions on such a variation, specifically, weighing documents not only on word counts but also on the number of times people linked to documents -- an early form of computerized social networking.
The most important point to take away from this is the subtle difference between databases and indexes. Libraries love lists. Lists of books. Lists of journals. Lists of author names and subject terms. Recently there are lists of databases and Internet resources. In a digital environment, lists are best maintained with relational databases because well-designed relational databases allow information to be stored in one place and associated with other information very efficiently. Databases are very good at the creation and maintence of lists. Unfortunately, databases do not excel at search. To effectively search a database a person (or the intermediary computer program) needs to know which database fields to query. This is very complicated and requires "bibliographic instruction". On the other hand, indexes, as outlined above, excel at search. There is very little need for query syntax, nor an understanding of how the data is structured, and results can be statistically enhanced. Databases and indexes compliment each other. They are two sides of the information retrieval coin.
Librarianship needs to learn how to exploit indexing techniques to a greater degree. While it would be best if the profession were able to master the mathematics of intelligent indexing, we can live with mastering the indexing applications themselves. Here are three open source software solutions:
- Swish-e - This application comes in both Windows and Unix/Linux flavors. It is command-line driven, and the same application that indexes the content is used to search it. It also comes with a number of "bindings" allowing you to integrate it with Perl, C, PHP, or a number of other scripting languages. This is a very good indexer to cut one's teeth on.
- Yaz/Zebra - The Yaz/Zebra combination is a grand daddy in Library Land. Originally designed to index MARC records and make the index available via the Z39.50 protocol, it has significantly evolved over time to allow just about any type of strutured data to be indexed and made searchable.
- Solr - The current open source software gold standard of indexers is the Java-based class called Lucene. Solr builds on Lucene's good work and made it better through a Web Services computing interface and the introduction of faceted search results. Once a Solr index/search engine is configured, all that is really needed to make it go is a Web browser coupled with XSL stylesheets. Not a lot of programming involved.
Exploiting technology
Finding books and articles is not the big problem that needs to be solved. Indexes and abstracts -- the tools of find -- are only a means to an end, not the end in itself. Yes, finding books and journal articles is important but not as important as using them. "Books are for use." People don't acquire books and journal articles just to have them. Instead, people want to do things with them. People want to read them, analyze their content, compare & contrast them with other content, verify a fact, trace an idea, be entertained, learn something new, be instructed on a process, etc. Finding data and information in books and journals takes a backseat to these other, more important, and relevant tasks. Finding information has been the work of librarians. Using it has been the work of everybody else, but with the advent of Google and social networking where friends make recommendations, find is not the challenge it used to be.
Instead I assert the library profession needs to go to the next step -- make content useful and provide services against it. Maybe one of the oldest services against texts is the concordance. In the late Middle Ages monks were creating such things against significant religious texts like the Bible. In essence, they were keyword-in-context indexes -- lists of specific keywords or phrases surrounded by other words from the text. Given a computer and full text, creating something like this programatically is not very difficult, and concordances are really useful for learning how a particular word or phrase is used. Figure 2 illustrates a concordance application of my own applied against Henry David Thoreau's Walden. Specifically, it looks for definitions of the word "man".

Figure 2, a simple concordance |
{kind=link}
Using similar technology, it is possible to see what words or phrases are used most frequently in a text. For example, Figure 3 illustrates the most common 100 individual words from Walden. From such a tool, can you glean what the text is about, or just as importantly, what the text is not about?

Figure 3, most frequently used 100 words |
{kind=link}
Even more interesting might be to learn what phrases are used most frequently in a text, as Figure #4 illustrates. Ironically, Ralph Waldo Emerson (Thoreau's mentor) describes Thoreau as a man who understands measures, and the most frequently used phrases illustrate such a thing.

Figure 4, most frequently used 100 phrases |
{kind=link}
Here is a service against texts of my own design. I call it the Great Ideas Coefficient. In the 1950s a man named Mortimer Adler and colleagues brought together what they thought were the most significant written works of Western civilization. They called this collection the Great Books of the Western World. Before they created the collection they outlined what they thought were the 100 most significant ideas of Western civilization. These are great ideas such as but not limited to beauty, courage, education, law, liberty, nature, sin, truth, and wisdom. Suppose you were to weigh the value of a book based on these ideas? Suppose you had a number of texts and you wanted to rank or list them based on the number of times they mentioned the "great ideas". Such a thing can be done through the application of TFIDF. Here's how:
- create a list of the "great ideas"
- calcuate the TFIDF score for each idea in a given book
- sum the scores for each idea
- assign the score to the book
- go to Step #2 for each book in a corpus
- sort the corpus based on the total scores
Once the scores are calcuated, they can be graphed. And once they are graphed they can be literally illustrated as depicted in Figure #5.
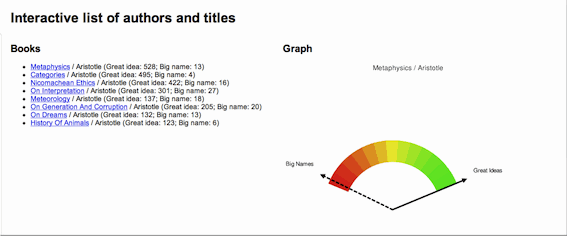
Figure 5, Great Ideas Coefficient |
{kind=link}
Notice how the graph changes for each title. This graph is generated based on the Great Ideas Coefficient for each work in the list. In other words, Aristotle's Metaphysics has the highest Coefficient and his History of Animals has the lowest.
All of the things listed in this section of this essay are simple examples of what can be done. More thorough examples are implemented by the researchers and scholars who call themselves digital humanists, and one of the best sites implementing these and more sophisticated tools is called TAPoRware:
TAPoRware is a set of text analysis tools that enables users to perform text analysis on HTML, XML and plain text files, using documents from the users' machine or on the web.
The TAPoRware tools were developed with support from the Canada Foundation for Innovation and the McMaster University Faculty of Humanities. These tools are being developed by Geoffrey Rockwell, Lian Yan, Andrew Macdonald and Matt Patey of the TAPoR Project for a TAPoR Portal which we expect to open in 2005.
Conclusion
Indexing and abstracting has come a long way since William Frederick Poole. With ubiquitous availability of computer processing power coupled with the increasing availability of full text and born-digital content, we have only just begun to scratch the surface of future possibilities.
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This presentations was created for an online library school class.
Date created: 2010-03-25
Date updated: 2010-03-25
Subject(s): abstracting; presentations; indexing;
URL: http://infomotions.com/musings/indexing-abstracting/