 DBMs and Web Delivery
DBMs and Web Delivery
Contents
- Introduction
- Filemaker
- Microsoft Access
- MySQL
- OBDC
- Conclusion: Databases and libraries
- Appendix A - An example CDML search form
- Appendix B - ASP script to add or delete a record from a table
- Appendix C - Perl/MySQL subroutines
- Links
Introduction
This presentation, DBMs and Web Delivery, compares and contrasts three database applications and describes how their content can be made available on the Web. Filemaker Pro is a cross-platform application including a built-in HTTP server. Combined with its extended markup language, Filemaker represents a quick and easy solution for many database needs. Microsoft Access is a more popular application employing SQL and ODBC facilitating greater scalability at the expense of learning ASP or the implementation of something like Cold Fusion as a means for Web distribution. MySQL, an open-source database application running under Unix is widely supported by the Internet community and is tightly integrated with the Perl programing language. Combined with HTTP servers like Apache, MySQL can meet just about any database requirement at the cost of a minimalistic user interface. (This presentation is also available as a one-page handout.)
Through this comparison a number of generalizations will become apparent: 1) small to mid-sized database applications can often times satisfy many information management needs, 2) each of the database applications described here have their own strengths and weaknesses, and 3) different database applications are more appropriate for different situations; "One size does not fit all."
Finally, the creation and maintenance of database applications and their content are essential to the work of libraries in the 21st century.
Filemaker
Filemaker is a cross-platform, desktop, relational database application. [1] Databases in Filemaker are really sets of "flat" tables linked together through file system specifications. The creation of tables is simplistic and the process of creating relationships between them relatively straight forward. If you move or rename the flat tables, then relations will break causing you to recreate the relations.
To say Filemaker is a cross-platform application is a tiny misnomer. Filemaker is supported under various Windows platforms (95, 98, and NT) as well as just about any Macintosh. It does not run under Unix. There is a single difference between Windows and Macintosh versions, and that difference is AppleScript. AppleScript is similar to Windows' Visual Basic for Applications (VBA) interface. It allows you to write programs querying Filemaker data and report on it's content. This is great when you want to create something other than simple tab-delimited or rudimentary HTML output from your database. Like many database applications, Filemaker's internal scripting language supports various string, numeric, and date functions for dynamically populating fields or reports. Unfortunately, one of these function is not file I/O.
Besides being extremely easy to use, Filemaker natively supports to essential Internet protocols for effectively providing access to your data via the Web: simple mail transfer protocol (SMTP) and hypertext transfer protocol (HTTP). This means Filemaker can be used as a user agent for sending email and it comes with a built-in Web server.
The implementation of both of these services relies on your ability to write HTML files in Filemaker's specialized mark-up language called Claris Dynamic Markup Language (CDML). CDML is really a server-side include sort of language. Looking a lot like HTML, it allows you to embed commands for adding, editing, deleting, and querying items in your database. ("What else is there?") As these commands are read by the Filemaker extension enabling HTTP serving they are interpreted and executed against your data. After results are obtained they are formatted into HTML and sent back to the Web browser initiating them in the first place. For example, to insert the current date as a CDML tag in your HTML files, you would include the following text:
<p> The current date is [FMP-CurrentDate]. </p>
After this tag was processed it might return something like this:
<p> The current date is Friday, September 17, 1999. </p>
CDML's real power, like all other server-side include extensions, is the ability to display dynamically created HTML forms, take the user-supplied input from those forms, and do some processing against the database. For example, you could create a staff directory database and then a CDML file/form listing every staff member's name in a pop-up menu. After selecting an item from the pop-up menu and submitting the form, Filemaker could return more specific information about the staff member including things like telephone number, email address, URL of home page, department, etc. Furthermore, this specific display could be a form itself allowing the authorized user to edit the information as necessary. A more complete example of CDML is listed in Appendix A.
Here in the NCSU Libraries we have been working on a bibliographic database implemented with Filemaker. The database/service is called Quick Response and resides on a Windows NT machine. [2] It allows users to browse and search the database via author, title, year, format, or a controlled vocabulary term. Controlled vocabulary terms of returned search results are hyperlinked allowing users to answer the proverbial question, "Find me more like this one." The service also allows users to request located items through a document delivery service. This is done via Filemaker's SMTP functionality. Once items are located a form can be displayed requesting the user's name and email address. This information, as well as the desired citation, are then emailed to a librarian for processing.
Personally, I use Filemaker to manage my set of professional web pages. By taking advantage of the relational database features and combining them with AppleScript, I am able to "classify" each of my professional HTML documents with controlled vocabulary terms. These vocabulary terms are automatically appended to the footers of my HTML documents and embedded as HTML META tags in the headers. Futhermore, I am able to change the value of global items like background images in a single record of the database and have the change ripple throughout my content. Finally, through the use of an AppleScriptable FTP client I am able to save content in my database, write it to my local disk, and have it uploaded to the proper place on the library's Web server. It's not perfect, but it works good enough for me.
Microsoft Access
Microsoft Access is the most popular relational database application here because it is a Microsoft product and it comes bundled with Microsoft's Office suite. [3] Access is more than capable of handling many of your database needs and combined with Microsoft's free Personal Web Server and a knowledge of the Active Server Pages scripting language you can make the content of your Access database(s) available on the Web. [4, 5].
Success in using Access depends on knowing when to use wizards and when not to use wizards. Not using the wizards to create your databases is straight-forward, but using wizards to create relations between tables is easier than doing it by hand. Creating Access database is much like creating databases in other applications, but unlike Filemaker, all your fields must be of a fixed length except for memo fields and binary (OLE object) fields. This is no big deal and simply enforces good database design.
Access has a number of very nice features when compared to Filemaker or MySQL. For one, multiple tables of Access databases are saved in a single file. This makes it more difficult to break your database's relations by simply moving the database file from one hard disk location to another. Similarly, all of Access's queries, forms, reports, and scripts are saved in the same file. The queries are graphically created SQL queries. The forms are database layouts made for each data-entry and querying. Reports are printed outputs of your data. The scripts are VBA (Visual Basic for Applications) modules providing the usual conditional tests, numeric and sting functions, and interfaces with outside applications and the operating system. Finally, Access's database structure reporting mechanisms excel. It is easy to create the standard illustrations describing the databases' structure and database dictionary. Using these functions greatly accelerates technically documenting your database(s) when compared to writing these documents by hand.
Making your Access database content available on the Web is best done through the combination of user-written Active Server Pages (ASP) and an ASP-capable HTTP server. True, Access can export datasets in HTML or rudimentary ASP but it is doubtful you will find the results acceptable because you will end up constantly tweaking the code Access creates and/or the code it creates will be dynamic in only the simplest sense. You are much better writing your own ASP in order to take complete control of the process.
Active Server Pages is a server-side include language similar to but more functional than CDML. By inserting special ASP tags in your HTML pages and making sure those pages are passed through an ASP knowledgeable server, the result is dynamically created content. For example, the following ASP code returns the current date and time of the Web server:
<p> The date is <% = Date %>, and the time is <% = Time %>. </p>
After this tag was processed it might return something like this:
<p> The date is 10/4/99, and the time is 2:38:38 PM. </p>
A much more elaborate example is listed in Appendix B. It is a part of a very simple online catalog containing tables for authors, titles, publishers, and subjects. The example provides the rudimentary means for adding or subtracting author names from an authority list. Here is how it works:
- A file, 00-RecToTable.asp, is "included", and it's purpose is to convert raw database output into a simple HTML table.
- A simple, static HTML form is rendered. Notice how the action attribute points to the ASP script itself.
- The script initializes a command that will be issued against the database.
- An object intended to contain the result of the command above is initialized.
- The content of the author field of the form is examined, and if it contains a value, then processing continues.
- Depending on the name of the button selected in the form, an add or delete SQL query is created and executed.
- A new command is executed extracting the value of all the authors in the table and displaying them in alphabetical order using the include file from Step #1.
Microsoft Access is an exceptional database application. It could easily serve as a platform hosting staff directories, mediums sized collections of Internet resources, lists of hardware and software supported by your library, bibliographies of just about any size, reference queries answered at a reference desk, items check in and checked out of medium sized collections, vacation and leave notices, digital images, etc. Its primary strength that it is a Microsoft application making it easily integrateable with other Microsoft application. This also means it is upwards compatible with larger scale applications like Microsoft SQL Server and/or Internet Information Server. The down side of Access is that it is a Windows-only application, and making your data available on the Web requires Microsoft products and a knowledge of ASP.
MySQL
MySQL is a relational database application running on Unix and Windows computers. [6] The Unix version is "open source" and comes with no licensing fees as long as you do not ask for technical support or you do not sell a product requiring MySQL. If you want technical support from the developers, then there is a fee based on a sliding scale. There is also a licensing fee associated with the Windows version of the application. MySQL seems to be the growing favorite in the Internet community. Only the Unix version is describe here.
What MySQL lacks in the user interface department it more than makes up for in functionality and scalabilty. It handles millions of records, supports the majority of SQL functions as well as auto incrementable, variable length, and binary (blob) fields. More importantly, MySQL supports an application programming interface (API) for C, Perl, and PHP.
Installing MySQL on your Unix computer is the processes of downloading the application in a pre-compiled format and running a few shell scripts. Alternatively, the process involves compiling the application yourself and running the shell scripts. This second alternative gives you more options for the location of the necessary files. In either case, the procedure is easy enough for a person who has installed the likes of Perl from source. Once installed it will be necessary to alter the permissions tables of MySQL allowing an authoritative user to create databases and provide access to them.
MySQL sports a minimalistic user interface and a number of programming interfaces. The user interface simply takes its input from a command line. Commands are standard Structured Query Language (SQL) statements: create, use, insert, select, delete, etc. For example, MySQL is used locally to maintain a list of agriculturally related serial titles. The project is code named Tomato Juice. [7] The content of these titles are intended to be indexed with an program called Harvest. Consequently, the Tomato Juice table includes fields for the serials' titles as well as a field denoting whether or not a title is to be indexed. The command to extract an alphabetical list of all the titles and their indexing value follows:
select serial_title, serial_indexed from serials order by serial_title;
It is also possible to create databases, tables, fields, and records via a shell script. This is good for batch processing. Like the other applications here, you can easily import and export data sets in plain text, tab-delimited formats.
While MySQL supports SQL, it does not support some of the features of its more robust relational database cousins like Sybase or Oracle. Specifically, MySQL does not support stored procedures, rollbacks, or triggers. According to the developers, the most important characteristic of MySQL is speed and these currently unsupported features, if implemented, will diminish its speed.
Command line interfaces are not for everybody and using the APIs supported by MySQL, developers can create applications taking advantage of MySQL and reducing the need to know or understand SQL. The more popular interfaces are C, Perl, and PHP. I have never used the C interface. Nor have I used the PHP interface, but PHP is becoming a more popular server side include language and its integration of MySQL is something well worth exploring. [8] The Perl interface (DBI::DBD for Msql-Mysql) provides all the necessary functionality for creating and maintaining databases. [9]
Using Perl for adding, deleting, and reporting on records in the Tomato Juice database is straight forward. For example the subroutines listed in Appendix C lists how a static HTML page can be created. The routines first define an SQL query that is passed the database. The database is searched and the results are put into a series of global arrays. An HTML file is then initialized and each record in the returned set of arrays is read and output to the HTML file. Finally, the HTML file is closed. A very similar process is used to dynamically create some of Harvest's configuration files.
MyLibrary@NCState, a user-driven, customizable, dynamically displayed portal-like application being developed in the NCSU Libraries is also rooted in MySQL. [10] The system is essentially a database application with a Web front-end. The database contains Internet resources and bibliographic items licenced by the Libraries. Each item is associated with one or more disciplines (subjects). As users create MyLibrary@NCState accounts they are asked to select a discipline. Consequently, a list of discipline-specific resources are displayed for the user. Similarly, librarians' names, who are associated with specific disciplines, appear on users' pages accordingly. Finally, the system allows users to add or subtract from the resources displayed on their page. The whole thing is done through the use of Perl and MySQL.
OBDC
Quite possibly the best solution for putting databases on the Web is not through the database application itself, but through a protocol called Open Database Connectivity (ODBC). [11] ODBC is yet another client server model of computing, and implements an SQL query-results transaction over a network. Essentially a database is set up as an ODBC "data source" allowing it to be queried. The data source acts as the server in a client/server computing model. A client formulates an SQL query and passes it through an ODBC "driver". The driver sends to the query on to the data source, waits for the reply, and finally returns the reply back to the client. The hard part in this scenario is getting the appropriate driver.
Microsoft Access and Filemaker can act as ODBC clients. Therefore you can construct SQL queries in Access or Filemaker, send those queries to remote databases, and download the results into the local database. More importantly, Access, Filemaker, and MySQL can act as servers, and scripting languages like Perl, PHP, or commercial programs like Allaire's ColdFusion or Blue World's Lasso can be used to query the databases. [12, 13] This model is more scalable than many of other techniques described in the previous sections since your ODBC-enabled scripts are oblivious to the databases being queried; the scripts only know about the driver. Therefore, your scripts could stay the same but your databases could move or your data could be migrated to a larger (or smaller) engines.
Conclusion: Databases and libraries
There seems to be no concrete formula for helping you decide what combination of database engines and scripting languages you should implement for making your data available on the Web. Most of the time your decisions will be made for you because you will be limited by particular pieces of hardware and software at your disposal. Even when you do have choices, those choices are hard to make. The largest of database applications such as Oracle or Sybase (often termed "enterprize solutions") will handle any database need but the administrative overhead may be more than you can handle. Desktop applications are easy to use as well as get up and running, but their functionality is limited by the number of records they can easily support as well as the number of simultaneous users.
This simple matrix illustrates one approach to selecting the appropriate database application for your need. Along one axis is the size of your database. Along the other axis is the number of simultaneous users you expect to use your database.
If you have a small number of records (<= 3000) and a small number of users (<= 25), then desktop solutions will work just fine. If you have a large number of records (> 3000) and a large number of users (> 25), then an enterprize solution is prescribed. The difficulty comes in when you have something in between and when you aren't certain about the number of users you expect to serve. This is when one of the open source combinations such as Perl/MySQL may be your best bet.
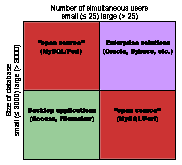
Database matrix |
{kind=link}
Libraries are becoming more and more about access (no puns intended) and less and less about storage. People can get their own information and more often than not this information does not necessarily come from a library. In order to provide access to information libraries routinely create lists of things such as books, journals, magazines, Internet resources, names, telephone numbers, addresses, etc. These lists are organized lists -- they are usually classified with one or more subjects describing the "aboutness" of each item. Using computers, organized lists are best implemented as relational databases.
It behooves librarians to learn and become experts in relational database technology so they (we) can take advantage of the flexibility and particular features of computerized lists. Computerized lists can be updated and copied easily, sorted and re-ordered, limited to subsets of lists, and incorporated into other data formats (ie. word processors, spreadsheets, charts/graphs, etc.) Combined with globally networked computers -- the Internet -- these same lists can be tranfered quickly and flawlessly from one place to another. This process is much a part of librarianship. It is akin to what we have described our role in society to be. Therefore it is appropriate for the us to learn how to use these tools effectively. Otherwise we will be doing our jobs in a manner than is less than professional.
Appendix A - An example CDML search form
This CDML file displays an HTML form used to search the contents of a database. The select options in this form are dynamically populated based on the contents of authority files and sets of controlled vocabulary terms saved in tables.
<!--show header--> [FMP-Include: header.inc ] <blockquote> <H1>Search</H1> <center> <p> <!--initialize the form and set a few defaults--> <form action="FMPro" method="GET"> <input type="hidden" name="-db" value="citations.fp3"> <INPUT TYPE="hidden" NAME="-lay" VALUE="all fields"> <input type="hidden" name="-format" value="results.html"> <input type="hidden" name="-Error" value="no-records-found.html"> <!--start a table--> <table border=1> <tr> <td align="right"><b>Field</b></td> <td><b>Operator</b></td> <td><b>Selection</b></td> </tr> <!--create an input for a title search with qualifiers and Boolean operations--> <tr> <td align="right">Title</td> <td> <select name="-op"> <option value="equals">equals <option value="contains" selected>contains <option value="begins with">begins with <option value="ends with">ends with </select> </td> <td> <input type="text" name="article title"> <input type="hidden" name="-lop" value="and"> </td> </tr> <!--create an input for an author search with qualifiers--> <tr> <td align="right">Author</td> <td> <select name="-op"> <option value="equals">equals <option value="contains" selected>contains <option value="begins with">begins with <option value="ends with">ends with </select> </td> <td><input type="text" name="authors"></td> </tr> <!--create an input in order to limit searches by year--> <!--notice how the select statement gets it's input from an internal list--> <tr> <td align="right">Year</td> <td>Equals</td> <td> <input type="hidden" name="-op" value="contains"> <select name="year"> <option value="" selected>(any year) [FMP-option: year, list=years] </select> </td> </tr> <!--create an input in order to limit by a format (article, book, video, etc.)--> <!--notice how the select statement get it's input from a related table--> <tr> <td align="right">Type</td> <td>Equals</td> <td> <input type="hidden" name="-op" value="contains"> <select name="types::type name"> <option value="*">(any type) [FMP-option: types::type name, list=type names] </select></td> </tr> <!--create an input in order to limit by a BROAD subject heading--> <!--notice how the select statement get it's input from a related table--> <tr> <td align="right">Category</td> <td>Equals</td> <td> <input type="hidden" name="-op" value="contains"> <select name="items4categories::category name"> <option value="*">(any category) [FMP-option: items4categories::category name, list=category names] </select></td> </tr> <!--create an input in order to limit by a NARROW subject heading--> <!--notice how the select statement get it's input from a related table--> <tr> <td align="right">Keywords</td> <td>Equals</td> <td> <input type="hidden" name="-op" value="contains"> <select name="items4keywords::keyword"> <option value="*">(any keyword) [FMP-option: items4keywords::keyword, list=keyword names] </select></td> </tr> </table> </p> <!--finally, submit the query--> <p> <INPUT TYPE="submit" NAME="-find" VALUE="Search"> <INPUT TYPE="reset" VALUE="Reset"> </p> </center> </form> </blockquote> <!--show footer--> [FMP-Include: footer.inc ]
Appendix B - ASP script to add or delete a record from a table
This ASP script displays an HTML form, processes input from the form, and displays all the values listed in a table.
<html>
<!-- #INCLUDE FILE="00-RecToTable.asp" -->
<head>
<TITLE>Authors</TITLE>
</head>
<body>
<H1>Authors</H1>
<!-- display an input form -->
<form method="post" action="./04-add-delete-author.asp">
author: <input name="author">
<input type="submit" name="button" value="Add">
<input type="submit" name="button" value="Delete">
</form>
<%
' create the command
set theCommand = Server.CreateObject("ADODB.Command")
theCommand.ActiveConnection = "DSN=OPAC"
theCommand.CommandType = 1
' create the record set
set recordSet = Server.CreateObject("ADODB.RecordSet")
' check for input
if request.form("author") <> "" then
' get the input
set theAuthor = request.form("author")
' get the name of the button
set theButton = request.form("button")
' branch according to the value of the button
select case theButton
case "Add"
' create an insert command and execute it
sSQL = "INSERT INTO authors (authors) VALUES ('" & theAuthor & "')"
theCommand.CommandText = sSQL
set recordSet = theCommand.Execute
case "Delete"
' create a delete command and execute it
sSQL = "DELETE FROM authors WHERE authorId = " & theAuthor
theCommand.CommandText = sSQL
set recordSet = theCommand.Execute
case else
' unknown button
response.write "Error: unknown button"
end select
end if
%>
<hr>
<H1>All authors</H1>
<%
' create a find request
sSQL = "SELECT * FROM authors ORDER by authors"
theCommand.CommandText = sSQL
' exectute the command and get fill the record set
set recordSet = theCommand.Execute
' display the result
response.write RecToTable (recordSet)
%>
</body>
</html>
Appendix C - Perl/MySQL subroutines
The subroutines below illustrate how Perl can be used to extract data from a MySQL database and dynamically create an HTML page of that content.
sub createSerialList {
# get all the titles
&getAllTitles ("select * from serials order by serial_title");
# open the output file
open (OUT, "> $outfile") || die "can't create serial list: $!";
# start the HTML
print OUT "<html><head>
<title>Tomato Juice serial list</title>
</head><body background=\"http://ag.arizona.edu/OALS/usain/tan.jpg\">\n";
print OUT "<blockquote>";
print OUT "<h1>Serials</h1>";
print OUT "<p>This is list of the serials to be included in the index.
This list is updated automatically as items are added and deleted
from the suggestion form.</p>";
print OUT "<ol>\n";
# process every title
for ($i = 0; $i <= $#ids; $i++) {
print OUT "<li><a href=\"$urls[$i]\">$titles[$i]</a> - $notes[$i]\n";
}
# end the HTML
print OUT "</ol>\n";
print OUT "</blockquote>";
print OUT "</body></html>\n";
# close the output
close OUT;
}
sub getAllTitles {
# get the query
my $q = @_[0];
# slurp up the database
$sth = $handle->prepare("$q");
if (!$sth) {print $handle->errstr;}
if (!$sth->execute) { print $handle->errstr;}
@ids = ();
@titles = ();
@urls = ();
@allows = ();
@denys = ();
@holdings = ();
@indexed = ();
@notes = ();
@contributors = ();
@emails = ();
while ($h = $sth->fetchrow_hashref) {
push (@ids, $h->{serial_id});
push (@titles, $h->{serial_title});
push (@urls, $h->{serial_url});
push (@allows, $h->{serial_allow});
push (@denys, $h->{serial_deny});
push (@holdings, $h->{serial_holdings});
push (@indexed, $h->{serial_indexed});
push (@notes, $h->{serial_note});
push (@contributors, $h->{serial_contributor});
push (@emails, $h->{serial_email});
}
}
Links
- Filemaker - http://www.filemaker.com/
- Quick Response - http://qrlib.tx.ncsu.edu/
- Microsoft Access - http://www.microsoft.com/office/access/
- Personal Web Server - http://www.microsoft.com/Windows/ie/pws/
- Active Server Pages - http://support.microsoft.com/Support/ActiveServer/ and http://msdn.microsoft.com/isapi/msdnlib.idc?theURL=/library/tools/aspdoc/iiwawelc.htm
- MySQL - http://www.mysql.org/
- Tomato Juice - http://hegel.lib.ncsu.edu/stacks/serials/tomato-juice/
- PHP - http://www.php.net/
- DBI::DBD - http://www.symbolstone.org/technology/perl/DBI/
- MyLibrary@NCState - http://my.lib.ncsu.edu/
- ODBC - http://msdn.microsoft.com/isapi/msdnlib.idc?theURL=/library/sdkdoc/dasdk/sdko4vcn.htm
- Allaire's ColdFusion - http://www.allaire.com/
- Blue World's Lasso - http://www.blueworld.com/blueworld/
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This was a presentation given to the staff of the North Carolina State University Libraries staff.
Date created: 1999-10-05
Date updated: 2005-05-15
Subject(s): databases; presentations;
URL: http://infomotions.com/musings/dbms-and-web-delivery/