 Cataloging Internet Resources: A Beginning
Cataloging Internet Resources: A Beginning
This presentation (given to the Tennessee Library Association, April 12th, Knoxville, TN) shares the beginnings of the NCSU Libraries attempt to catalog Internet resources and make them available through a WWW interface. The presentation will share how we integrated Tim Kambitsch's' "unnamed" scripts into one of our WWW server enabling us to search our OPAC through a WWW interface. The presentation will describe SID (Simple Internet Database), a program we use to create and maintain the majority of the HTML files on our WWW server. Additionally, a description of how these pieces of software are being integrated into the Alcuin database, a database of Internet resources. Finally, philosophic issues will be raised concerning the cataloging and classification of Internet resources. (An abreiviated version of this text is also availble as a one-page PDF file designed as a handout.)
The NCSU Libraries "Library Without Walls" and "Study Carrels"
When gopher was the big Internet protocol, the Libraries was giving Internet classes to the University's students, faculty and staff. Invariably, when giving these classes, I carried with me great tomes of Internet guides and people would ask me lists of resources concerning particular subjects.
Getting tired of carrying this large books to the class, I heard of a smaller library in the Midwest that thought of organizing Internet resources on a gopher server. Picking up on this idea, I structured the Gopher at the NCSU Libraries using a what I called the "Used Bookstore Model". In this model very broad subjects were created matching the same sorts of subject heading commonly found in used book stores. I called the these classifications "study carrels" because in libraries student bring together materials and put them in their study carrels. Most likely, these collection of information materials consist of similar subjects. The idea became very popular and seemed to be model for about a year.
Hunter Monroe and Alex
About this time I made contact with Hunter Monroe. Hunter, an economist by profession and a person who has done some computer work for the cataloging department at the Bodleian Library of Oxford University, had been maintaining a list of textual Internet resources. His goal was/is to create a OPAC-type database of Internet resources. He called his database Alex:
Alex allows users to find and retrieve the full-text of documents on the Internet. It currently indexes over 700 books and shorter texts by author and title, incorporating texts from Project Gutenberg, Wiretap, the On-line Book Initiative, the Eris system at Virginia Tech, the English Server at Carnegie Mellon University, and the on-line portion of the Oxford Text Archive. For now it includes no serials. Alex does include an entry for itself.
The NCSU Libraries was lucky enough to foster a relationship with Hunter, and consequently, the NCSU Libraries has hosted his data on our gopher server. The format of the gopher server has changed since its inception, but the concept remains the same. Hunter named his database Alex. David Price of Radcliffe Science Library, Oxford University hosted the first version of Alex at Oxford.
Because every information system has to be browsable as well as searchable, the NCSU Libraries indexed the Alex database using the jughead technology. Later, since the hypertext transfer protocol (HTTP, and commonly called the World Wide Web or WWW for short) was becoming popular, the NCSU Libraries experimented with methods of providing access to the Alex database via WWW browsers. While WWW browsers can interpret the gopher protocol, the WWW browsers were not being used to their fullest extent. Consequently, Hunter was asked to create a specialized report that would be easily indexable using the WAIS technology. Hunter obliged and a WWW interface to Alex was created. Up until this time Alex had been maintained in a dBase IV database which creates gopher links; the database was not directly queried.
Working with Monroe, we learned he was maintaining his collection through the use of a database application. Each record in his application contained fields describing each Internet resource in terms of title, author, date, location, and (eventually) subjects. At the outset, the Alex database was made available through a gopher server. To this end, Monroe used his database application to automatically create gopher link files, the substance of gopher servers. With just a bit of encouragement, Monroe was able to modify his database application and create hypertext markup language (HTML) documents as well. The Alex database has proven to be a model for the rest of our development work.
Tim Kambitsch and Searching OPACs with WWW Browsers
At the same time I had been working with Tim Kambitsch then of Butler University on scripts to search our OPACs with WWW browsers. These scripts, both form-based and non-form-based, allow the user to specify Boolean queries to be applied to user-selected databases (book and journal catalogs, catalogs of government documents, and potentially bibliographic indexes like Academic, Business, or Newspaper Index). Thus you can search our catalogs through your WWW browser by using the following URL: http://library.ncsu.edu/
Mr. Serials and the 856 Field
At the 1994 Annual Meeting of NASIG, I formally described the Mr. Serials process for collecting, organizing, indexing, and disseminating electronic serials. You use the link http://www.lib.ncsu.edu/staff/morgan/mr-serials-at-NASIG.html to read an outline of the presentation.
During the Meeting I became more aware of the proposed MARC 856 field. This field is intended to describe the locations and holdings of electronic documents. It has provisions for things like the name of remote files, the operating system of the remote computer, the protocol used to communicate with the remote computer (FTP, telnet, or other), the directory where the remote file resides, et cetera. I learned about the 856 field by reading "Proposal No: 93-4", USMARC Format: Proposed Changes 1993, No. 2. prepared by the Network Development and MARC Standard Office. ("How do as a person cite such a thing?")
I thought it would be a good idea to catalog Mr. Serial's collection of electronic journals and newsletters, as well as include a Universal Resource Locator (URL) in an 856 field. This way users could search our OPAC, select the URL from the screen, and paste it into their favorite WWW browser.
Since I could now search my OPAC with a WWW browser, and since I could now list an access points to electronic items in my catalog, the next logical conclusion was to provide a hypertext link from my catalog to the electronic item itself. This is just what I did, as well as the point to this article.
I proceeded to download two MARC records from OCLC (OCLC record numbers 26226155 and 20987125). These records describe ALAWON and Public Access Computer Systems Review (PACSR), respectively.
I then imported these records into our OPAC's database.
I then edited the records to include 856 fields. (Shown below.)
- ALAWON - 856; ; a <a href='http://www.lib.ncsu.edu/stacks/alawon-index.html'> http://www.lib.ncsu.edu/stacks/alawon-index.html</a> $
- PACSR - 856; ; a <a href='http://www.lib.ncsu.edu/stacks/pacsr-index.html'> http://www.lib.ncsu.edu/stacks/pacsr-index.html</a> $
Notice how I not only included the URL's in the 856 field, but I also made those URL's hypertext links by surround them with HREF's (<a href='http://www.lib.ncsu.edu/stacks/alawon-index.html'></a> and <a href='http://www.lib.ncsu.edu/stacks/pacsr-index.html'></a>).
By adding these URL's and HREF's to my MARC records, and by searching my OPAC for these records, the user then has the opportunity to navigate directly to the electronic resource after located items of interest.
This worked so well I went on to edit a record describing the North Carolina State University's recent self-study (North Carolina State University, self study report) which exists not only in paper form but electronically as well.
To see the results of these labors in action:
- Use your WWW browser to access http://library.ncsu.edu/.
- Choose either the forms-based or non-forms-based searching methods.
-
Search for:
- "alawon", or
- "public access computer systems review", or
- "ncsu self study".
- Display the results in "full" or "MARC" format.
- Look for the links in the resulting texts and give them a try.
- Think (and thinque) of the implications of this process.
The MARC record below describes an electronic newsletter called ALAWON. This record was imported into our OPAC and edited to include an 856 field.
AFW-1740 Entered: 06/16/1994 Last Modified: 02/21/1995 NCSU_CATALOG
Type: a Bib l: s Enc l: Desc: a Ctry: dcu Lang: eng Mod: Srce: d Freq:
Reg: x ISDS: 1 Ser t: Orig f: Form: Entire C: Cont: Gvt:
Cnf: 0 Alpha: a S/L: 0 Pub s: c Dates: 1992 9999
003; ; a OCoLC $
005; ; a 19940616115148.0 $
010; ; a sn 93004037 $ o 26226155 $
040; ; a VPI $ c VPI $ d NSD $
012; ; l a $
022; 0 ; a 1069-7799 $
042; ; a nsdp $ a lcd $
082; 10; a 025 $ 2 12 $
090; ; a Z673.A5 $ b A42 $
049; ; a NRCC $
210; 0 ; a ALA Wash. Office newsline $
212; 1 ; a American Library Association Washington Office newsline $
222; 0; a ALA Washington Office newsline $
245; 00; a ALA Washington Office newsline $ h [computer file] : $ b ALAWON :
an electronic publication of the American Library Association
Washington Office. $
246; 10; a ALAWON $
260; ; a Washington, DC : $ b The Office, $ c [1992- $
265; ; a American Library Association Washington Office, 110 Maryland Ave.,
NE, Washington, DC 20002-5675 $
310; ; a Irregular $
362; 0 ; a Vol. 1, no. 1 (July 9, 1992)- $
500; ; a Mode of access: Electronic mail on BITNET; listserv@uicvm;
SUBSCRIBE ALA-WO First Name Last Name $
500; ; a Title from title screen. $
650; 0; a Libraries $ z United States $ x Periodicals. $
650; 0; a Information services $ z United States $ x Periodicals. $
610; 20; a American Library Association. $ b Washington Office $ x Periodicals.
$
710; 20; a American Library Association. $ b Washington Office. $
936; ; a Vol. 2, no. 18 (May 10, 1993) LIC $
856; 00; u http://www.lib.ncsu.edu/stacks/alawon-index.html $
The MARC record below describes an electronic journal, The Public Access Computer Systems Review. This record was imported into our OPAC and edited to include an 856 field.
AFW-1741 Entered: 06/16/1994 Last Modified: 06/17/1994 NCSU_CATALOG
Type: a Bib l: s Enc l: 7 Desc: a Ctry: txu Lang: eng Mod: Srce: d Freq: t
Reg: r ISDS: 1 Ser t: p Orig f: Form: Entire C: Cont: Gvt:
Cnf: 0 Alpha: a S/L: 0 Pub s: c Dates: 1990 9999
003; ; a OCoLC $
005; ; a 19940616115330.0 $
010; ; a sn 90000811 $ o 20987125 $
040; ; a NSD $ c NSD $ d CAS $ d NSD $
012; ; j 1 $ l a $
022; 0 ; a 1048-6542 $
030; ; a PACRES $
042; ; a nsdp $ a lcd $
082; 10; a 025 $ 2 11 $
049; ; a NRCC $
210; 0 ; a Public-access comput. syst. rev. $ b (Electron. ed.) $
222; 4; a The Public-access computer systems review $ b (Electronic ed.) $
245; 04; a The Public-access computer systems review $ h [computer file]. $
246; 10; a Public access computer systems review $
246; 13; a PACS review $
250; ; a [Electronic ed.]. $
260; ; a Houston, TX : $ b University Libraries, University of Houston, $ c
1990- $
265; ; a PACS Review, c/o University Libraries, University of Houston,
Houston, TX 77204-2091 $
310; ; a Three times a year $
362; 0 ; a Vol. 1, no. 1- $
500; ; a Mode of access: Electronic mail on BITNET and Internet; Send an
e-mail message to: (BITNET) LISTSERV@UHUPVM1 or (Internet)
LISTSERV@UHUPVM1.UH.EDU that says: Subscribe PACS-P First Name Last
Name; also available through a subscription to the Public-access
Computer Systems Forum, PACS-L@UHUPVM1.BITNET $
500; ; a Description based on printout of online display; title from title
screen. $
580; ; a Also available in an annual print ed. under the same title. $
710; 20; a University of Houston. $ b Libraries. $
775; 1 ; t Public-access computer systems review (Print ed.) $ x 1063-164X $ w
(DLC)sn 92004809 $ w (OCoLC)25907292 $
856; ; u http://www.lib.ncsu.edu/stacks/pacsr-index.html $
Alex Meets Alcuin
The NCSU Libraries has also wanted to create a database of Internet resources. To that end, using our DRA OPAC software we created a new database named Alcuin and employed the DRA-WWW gateway scripts Tim Kambitsch.
(Alcuin of York (b. circa 735 - d. May 19, 804) was a Medieval librarian and advisor to Charlemagne. A respected scholar of the time, Alcuin was a driving force behind the Carolingian Renaissance. Alcuin is being honored here because he exemplifies the ideals of librarianship. He took the learning of his time, organized it, and provided a means for disseminating it for the benefit of society.)
After discovering the difficulty of creating original cataloging records using the DRA's netcat program, we decided to create our own USMARC record editor.
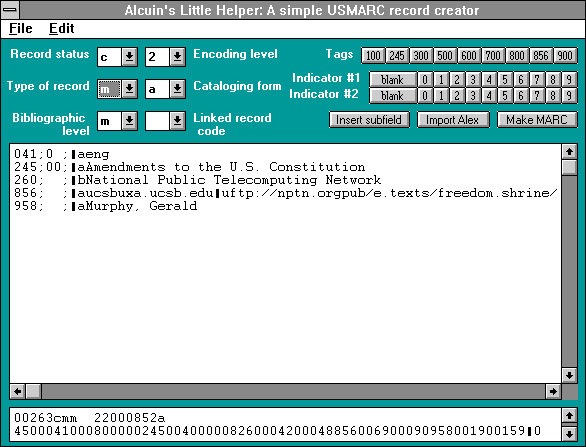
Monroe's output was then processed with a locally developed utility called Alcuin's Little Helper. Alcuin's Little Helper, written in VisualBasic and running under Microsoft Windows, is based on:
The OS/2 Visual REXX program used to create LC MARC records [. It] is the result of a joint effort by Dick Thaxter and David Williamson to provide a more graphical and user-friendly interface between catalogers, electronic texts, and the systems used to create MARC records at LC.
In short, Alcuin's Little Helper is a very simple MARC record editor. It can be used to create MARC records by hand or convert Monroe's tagged output to MARC records.
This is screen shot of Alcin's Little Helper, a very simple MARC record editor. By selecting the buttons and pasting text, the cataloger can create valid MARC records for their OPAC database. Alternatively, the cataloger can import the output shown in Figure 3 to create MARC records as well. The process takes about 15 minutes to process all of the data in the Alex output file. This program and its source code are available at for download.
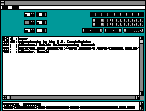
Alcuin's Little Helper |
{kind=link}
Using Alcuin's Little Helper, Monroe's tagged output was imported and converted into true, rather simplified MARC records.
These are three MARC records are examples of tagged manifestations of the MARC records created by Aluin's Little Helper. These records were created from the files listed above. The sum of these records, in true MARC communications format, is available at ftp://ftp.lib.ncsu.edu/pub/stacks/alex/alex-950224-marc.txt and should be completely compatible with any OPAC database software.
DBCN: PAA-0647 Entered: 03/13/1995 Modified: 03/13/1995
Type: m Bib l: m Enc l: 2 Desc: a
041; 1 ;a angeng $
100; 1 ;a Plato $
245; 00;a Collected works $
700; 1 ;a Jowett, Benjamin $d 1817-1893 $
856; ;u gopher://gopher.vt.edu:10010/01/131 $
959; ;a Philosophy $
DBCN: PAA-0481 Entered: 03/13/1995 Modified: 03/13/1995
Type: m Bib l: m Enc l: 2 Desc: a
041; 1 ;a angeng $
100; 1 ;a Aristotle $
245; 04;a The Athenian constitution $
260; ;c BC $
700; 1 ;a Kenyon, Frederic G. (Frederic George), Sir $d 1863-1952 $
856; ;u gopher://gopher.vt.edu:10010/02/39/3 $
959; ;a History $
DBCN: PAA-0386 Entered: 03/13/1995 Modified: 03/13/1995
Type: m Bib l: m Enc l: 2 Desc: a
041; 0 ;a eng $
100; 1 ;a Twain, Mark $d 1835-1910 $
245; 04;a The adventures of Huckleberry Finn $
260; ;a New York $b Harper & Brothers $c 1912 $
773; ;a Writings of Mark Twain Volume XIII $
856; ;s 390k $u gopher://wiretap.spies.com:70/00/Library/Classic/huckfinn
mt $
956; ;b 1912 $
957; ;a PG 76 WT $b pg/etext93/sawyr10.txt $
958; ;a Dell, Thomas $b dell@wiretap.spies.com $
959; ;a Fiction $
These records were then imported into a newly created DRA database and made available through Kambitsch's gateway scripts. This is a screen shot of the Alcuin database as it appears in a WWW browser's window. The database itself is available itself at http://library.ncsu.edu/drabin/alcuin/. Using this interface you should be able to search the contents of the Alex database. The database consists of MARC records containing URLs in the 856 fields. The interface this service works through is based on Tim Kambitsch's DRA/WWW gateway scripts and translates the contents of subfield u of 856 fields into "hot links."

Alcuin' Database of Internet Resources |
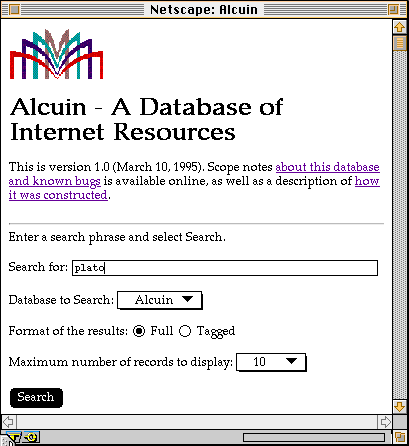{kind=link}
Thus, the Alcuin database was born.
Simple Internet Database (SID)
In an effort to mirror Hunter Monroe's ideas, we created a database of our own. We called this database the "Simple Internet Database" or SID for short. The application was written in HyperTalk, the language of HyperCard. Each record in the database contains a field for title, author, date, URL, abstract, major subjects, and minor subjects.
Internet resources were added to the database after being evaluated in terms of their identifying elements. Most of the database's records were completed in a straight forward manner; it is usually not too difficult to determine the title, author, and URL of Internet resources. Abstracts were included to facilitate future keyword searching. They were copied, when available, directly from the Internet resources themselves and pasted into the records.
The database was designed to accommodate as many major and minor subject entries as needed. Since, at the present time, the breadth and quality of Internet resources does not match the breadth and quality of our printed resources, and since the controlled vocabulary of our traditional database applications (OPACs) does not seem to fully satisfy the needs of our clientele, we began creating our own controlled vocabulary. This controlled vocabulary, admittently, was not created systematically. Rather, when a "critical mass" of Internet resources presented themselves that seemed pertinent to the educational and research needs of the our clientele, a new, major and/or minor subject term was created. Presently, the controlled vocabulary contains about two dozen terms. Minor subjects usually represent the form of Internet resources or sub-subjects. We have created quite a number of minor subject terms.
Learning from our experiences taken from Hunter Monroe, reports can be created based on the contents of the database. At the present time, these reports are HTML documents. Each document contains all the records matching sets of major subject/minor subject pairs. After the documents have been created they are saved in a directory of the library's WWW server. These files form the bulk of our server. Access to these documents is then provide via browsing as well as a searchable, keyword index. Field searching is not supported.
Revisiting the concept of a catalog
Just like any other information format, bibliographic records describing Internet-based electronic serials should be included in our OPACs. The basis of this opinion lies in my definition of a library catalog. The library catalog is a finding aid. More specifically, it is a tool designed to help a defined set of people locate information in a comprehensive collection of data. As we improve the functions of our OPAC software, this finding tool will also become an access tool. This position can be contrasted with the idea of a library catalog as a list of things owned by a library and are held within a library's walls. Put another way, if you were ask me to address the "access versus ownership" issue, then I would fall, for the most part, in the "access" camp.
The decision to define an OPAC as a finding tool as opposed to a simple catalog represented a personal, internal, and professional debate raging inside of me for more than a year. Defining an OPAC as a simple catalog or list of materials owned by a library would have made many of the problems listed below seem irrelevant. It would have made our life as librarians much easier and less complex.
On the other hand, if we limit our OPACs to only items we own, then we are doing our user populations a great disservice. This is because many valid information resources exist beyond our immediate control but still prove very useful to our clientele. If we restrict the inclusion of Internet resources from our OPACs, then we do not evolve with the times and provide the sorts of services our user populations have come to expect and desire. Furthermore, if libraries do not provide these sorts of services, then commercial services will. Consequently, libraries would be lackadaisical in fulfilling their mission of equal access to information, especially considering that many Internet resources are freely available.
Incidentally, taken to the extreme, if the OPAC is a finding tool and Internet resources should be included in the OPAC, then we must ask ourselves why we are not including the data from bibliographic journal article indexes as well. If the OPAC is suppose to be a comprehensive finding aid, then a logical conclusion to this proposition seems to point to the inclusion of bibliographic journal article indexes as well as Internet resources. The differences in controlled vocabularies, the skills needed to limit searches to particular formats, and the mixture of formats themselves are all possible rebuttals to this seemingly logical conclusion. Fortunately (or unfortunately), the development of this consequence is not the topic of the present discussion.
Broken URLs and the hopes for URIs
There are a number of obstacles impeding a library's ability to effectively add bibliographic records of Internet-based serials to its OPAC. The first is the dynamic nature of the Internet, and therefore, the dynamic nature of the serials. We have all experienced the "file not found" errors on our own local computers as well as remote Internet-based computers. If a library were to rely on the addition of uniform resource locators (URL) in the 856 fields of MARC records, then librarians may spend much of their time tracking down "broken" URLs. Hopefully, the concept of the uniform resource identifier (URI) will come to fruition and reduce (if not eliminate) the numerous reasons why the "file not found" error occurred in the first place.
As you may or may not know, URIs are to URLs as the Internet names of computers are to Internet Protocol (IP) numbers. All computers on the Internet are uniquely identified by IP numbers. For example, the IP number of the computer on my desk is 152.1.24.177. This computer has a name as well, emorgan.lib.ncsu.edu. If I were to get a new computer it would be assigned a new IP number, but the domain name service (DNS) of our campus could make sure the new number would be associated with the old name. Thus, I could always tell be people to connect to my computer (emorgan.lib.ncsu.edu) and they would find it available.
URIs will work the same way. There will be a database of URIs. Each one will be associated with one or more URLs. As URLs change, the database is updated. To use the Internet, people would use URIs instead of URLs and consequently, URIs would never be broken as long as the database were kept up-to-date.
Until the concept of a URI becomes a reality, I can imagine a number of short-term solutions to this problem. The least likely solution is the addition of a new feature to OPAC software by vendors. This feature would examine all the records in the database(s) containing 856 field(s) and check for the validity of the URL(s) found there. Invalid URLs would then be added to a list and regularly sent to a database maintenance team.
A more likely solution is to do this ourselves using the report generation services already included in our OPAC software. Another solution, and quite possibly the most implementable, is the creation of a separate, locally maintained database of Internet resources. This database is not necessarily MARC-based, but it would contain the fields essential to create a complete MARC record. More importantly, it would be able to extract the URL of a record and check for its validity. Then, on a regular basis, when all the URLs had been verified, this database would create a report in the form of MARC records, and these records would be imported into the OPAC overwriting any duplicates found there. Realistically, none of these solutions are ideal, but may be necessary for the short-term.
Integrating identification and access
Another impediment to the effective use of a Internet resource in our OPACs is accessing the Internet resources once they has been located. In other words, after a Internet resource has been located in the OPAC, how does the end-user actually get that resource? In most of today's cases, the end-user would have to extract the URL from the MARC record and use their Internet communications software to open up the extracted URL. Not only is this analogous to the writing down call numbers where many end-user mistakes occur, but it should be unnecessary.
A user of the OPAC should be able to access the resource from the same piece of software they use to access the OPAC. Unfortunately, many of the computers used to access the OPAC are not really computers at all. They are "dumb terminals" incapable of opening multiple windows and supporting concurrent applications.
The solution to this problem is three-fold. First, we should eliminate the use of dumb terminals in our libraries and rely on "smart terminals" (computers) to access the OPAC. Second, we should impress upon our OPAC vendors the need for microcomputer-based front-ends to their systems. Third, these front-ends should be aware of 856 fields and allow people to use the URLs found there to access Internet-resources. By "aware of 856 fields", I mean the OPAC software could extract the URLs or (URIs) in an 856 field, interpret the protocol of Internet resource represented there, and then open up a connection to the remote computer using that protocol. This means the OPAC software would also have to be FTP, gopher, email, telnet, hypertext transfer protocol (HTTP), as well as future clients.
An alternative, more likely, solution is the further development of Z39.50 and/or World Wide Web interfaces to OPACs as exemplified by the demonstration interfaces listed in "Library Catalogs with Web Interfaces" and "WWW-to-Z39.50 Gateways." These interfaces can interpret the contents of the 856 field and make them "hot" for our browser software. This is how the Alcuin database works. When searches locate records containing URLs in 856 fields, the interface program extracts the URL and creates an very simple hypertext markup language (HTML) document. Thus, when the document is returned to the client application the URLs are "hot."
Enhancing the controlled vocabulary
While the incorporation of bibliographic records describing Internet resources into our OPACs presents some technical difficulties, this proposition also challenges our controlled vocabulary systems. The controlled vocabularies of our OPACs have always been hallmarks of their usefulness and integrity. Much of the North American academic libraries rely on the Library of Congress Subject Headings (LCSH) for their controlled vocabulary. LCSH was intended to be the vocabulary of the Library of Congress and not necessarily North America; the Library of Congress is not a national library and their vocabulary is designed for their particular needs. Consequently, LCSH does not always include the vocabulary to adequately describe items in our OPACs. This problem is magnified by the length of time necessary to introduce new terms into LCSH.
Since Internet resources "come to market" much faster than traditional information materials, and the types of information they represent are even more specialized than traditional materials, Internet resources can limit the usefulness of our controlled vocabularies even more. Thus, the incorporation of Internet resources into our OPACs will necessitate a faster method for including and updating our controlled vocabularies. I would like to advocate a new and improved source for our controlled vocabularies, but I do not know how to implement such a thing.
Labor intensitivity and new skills
Initially, the addition of Internet resources into our OPACs will be a labor intensive process since many of the records will require original cataloging. Since the Library of Congress is not currently producing 856-aware cataloging records, libraries who want to include these sorts of records will have to create their own. It will take time for our bibliographic utilities to obtain a critical mass of these sorts of bibliographic records.
Until such a time occurs, many records will have to be created individually. This will require more professional catalogers with an in-depth knowledge of the Internet and time to evaluate Internet resources in terms of their bibliographic elements. Since Internet resources do not have title pages and versos, these catalogers will have to reinterpret the rules of cataloging and classification in order to create these new records. (A list of guides and references discussing how to catalog Internet resources can be found in Vianne Tang Sha's "Internet Resources for Cataloging."
Once a critical mass of Internet resources appear in our bibliographic utilities, copy cataloging will again become the norm, but again, since Internet resources "come to market" so much faster than familiar mediums, and since relatively few libraries are contributing 856-aware cataloging copy, there will be the constant need for more original cataloging than is traditionally done by our libraries.
End-user education
With the wide-spread addition of the bibliographic records describing Internet-resources into our OPACs will come a need to educate our populations on the existence of these records in our OPACs. Furthermore, libraries will have to try to distill from the population's mind set that an OPAC is "only a list of books."
Numerous collections of Internet resources are appearing on the Internet. Many of these collections support search features. Experience demonstrates that these same search features rely solely on free-text searching; while Boolean logic and relevance ranking are employed by these services, controlled vocabulary and field searching are not supported. Despite these limitations, these services are extremely popular. People may begin to think they are the only useful collections of Internet resources.
Unless libraries aggressively incorporate Internet resources into their OPACs which are pertinent to the needs of their user populations quickly and effectively, the search services will be come the norm and our user population will not understand the benefits of our OPAC's selectiveness and comprehensiveness. In other words, libraries will continue collecting information resources particularly useful to their clientele and attempting to create a thorough and extensive collection as possible at the same time.
Additionally, since the OPAC is more than "a list of books", but our populations don't comprehend this, our populations will have to be educated on how to use and access any located Internet resources from the collection.
A Catalog's Definition Refined
The definitions of traditional and enhanced catalogs always assumed the materials (objects) of the catalog were physical in nature. Since the objects were only physical in nature, maybe it seemed fruitless to list items beyond the library's control. Catalogs are big and difficult to maintain even considering the number of items any one library owns. The problem would be even worse for items not directly under a library's control.
With the advent of electronic items, and the desire to make the catalog a finding aid, information resources found their way into library catalogs, even though these resources were not owned by the library. Thus, the catalog has become a tool more akin to a bibliography as oppose to a simple list. In keeping with this idea, records have appeared in library catalogs pointing to electronic-only bibliographic indexes available only through online database vendors like DIALOG.
These electronic items, unlike physical items, are more "readily-available"; these items, assuming well maintained Internet sites and reliable connections, can be just as accessible, if not more so, than physical materials. Furthermore, these items have as much information value as many other objects in library catalogs. Therefore, since modern catalogs can be seen as finding aids to information on given subjects, and since Internet resources have as much value as traditional mediums, Internet resources should be included in library catalogs. This is seen as necessarily true when the definition of library catalogs is refined as in:
A library catalog is an organized list of information resources arranged in all or any number of schemes (author, title, subject, accession, size, type, etc.) and these resources are readily-available to the intended clientele of the organized list.
Formalizing a process
The ultimate goal (or end) of the Alcuin Project is to create a systematic method for cataloging and classifying electronic serials and Internet resources. At the North Carolina State University (NCSU) Libraries we believe we have successfully outlined the work flow of such a method. It does not differ very much from traditional acquisition strategies. This is how it may work:
- The collection management department, in conjunction with "subject teams" will select resources for inclusion into a database of relevant items.
- The URL describing the resource is passed on to our cataloging department who analyze the resource in terms of its author, title, notes, subjects, etc.
- The results of this analysis is used to update a database program.
- Reports, based on the content of the database, are then generated updating our dissemination tools namely, an online catalog and our World Wide Web (WWW) server.
The Collection and Acquisitions Process
Before an item can be put into the Alcuin database, it must be selected and possibly acquired. This aspect of the process may be handled by the collection management and acquisitions departments, respectfully. First, our collection management department "listen" to the Internet. Based on its knowledge of the needs of our clientele, collection managers select Internet resources to be added to the database. If the Internet resource is an item the library actually wants to own, then a URL pointing to the resource is passed on to the acquisitions department. At that time, the acquisitions department retrieved the item and put it in an "electronic inbox" for the cataloging department. If the Internet resources is not something the libraries wants to own, then the URL pointing to the resource is passed directly to the cataloging department bypassing the acquisitions department.
Creating and Adding Items to Alcuin
Once a cataloger became aware of a new item to added to the database, the cataloger used his/her professional skills to analyze the resource and create a MARC describing the resource based on their analysis. To ease the creation of these original records, Alcuin's Little Helper, which allows a cataloger to cut, copy, and paste data from various Internet client applications, will be used. The records generated by Alcuin's Little Helper are then be added to the Aluin database.
Providing Access to Alcuin
Providing effective access to any information system requires varying degrees of browsablility and searchability. To facilitate our clientele the ability to browse Alcuin an HTTP server will be put into place. The data contained on this server will be generated on regular basis from the contents of the Alcuin database. This data will essentially be a large set of hypertext markup language documents.
The ability to browse an information system has its advantages and disadvantages. By providing a method for searching an information system some of those disadvantages can be overcome. More specifically, the DRA/WWW gateway scripts will provide the search features for the database.
Summary
The inclusion of Internet resources into our OPACs presents fundamental challenges to our conceptions of a library catalog. It also presents technical difficulties, as well as semantic ones. It necessitates a lot of end-user and librarian education and retraining. None of these obstacles are unsurmountable. The solutions require persistence, ingenuity, and a respect for change. In short, they require a propensity for professionalism and a commitment to excellence in service.
Creator: Eric Lease Morgan <eric_morgan@infomotions.com>
Source: This presentation was originally given at the Tennessee Library Association, April 12, 1996, Knoxville, TN.
Date created: 1996-04-12
Date updated: 2005-05-21
Subject(s): presentations; TLA (Tennessee Library Association); cataloging;
URL: http://infomotions.com/musings/cataloging-resources/