

Oddly enough, the human-computer interaction of traditional online searching is not very much unlike the client/server model of computing, the principle computing metaphor used for Internet communications.
To truly understand how much of the Internet operates, and especially for information seeking on the Internet, it is important to understand the concept of client/server computing.
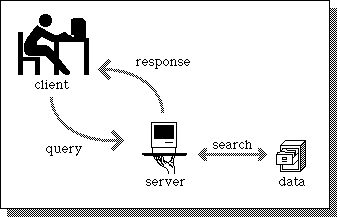
The client/server model is a form of distributed computing where one program (the client) communicates with another program (the server) for the purpose of exchanging data.
The client's responsibility is usually to:
- Handle the user interface.
- Translate the user's request into the desired protocol.
- Send the request to the server.
- Wait for the server's response.
- Translate the response into "human-readable" results.
- Present the results to the user.
The server's functions include:
- Listen for a client's query.
- Process that query.
- Return the results back to the client.
A typical client/server interaction goes like this:
- The user runs client software to create a query.
- The client connects to the server.
- The client sends the query to the server.
- The server analyzes the query.
- The server computes the results of the query.
- The server sends the results to the client.
- The client presents the results to the user.
- Repeat as necessary.
This client/server interaction is a lot like going to a French restaurant. At the restaurant, you (the user) are presented with a menu of choices by the waiter (the client). After making your selections, the waiter takes note of your choices, translates them into French, and presents them to the French chef (the server) in the kitchen. After the chef prepares your meal, the waiter returns with your diner (the results). Hopefully, the waiter returns with the items you selected, but not always; sometimes things get "lost in the translation."
The process of providing traditional online searching services is also a lot like the client/server model of computing. For example, suppose you were to provide traditional online searching services. This is how it would work:
- A person would approach you (you're the client program) and express an "information need."
- You would ask the person a number of questions allowing you to translate their need into a search strategy (the protocol).
- Next, you, the client, would send the search strategy, the protocol, to the remote database (the server)
- Wait for a response
- Interpret it.
- Present it to the person.
It is important to know about client/server computing in the Internet environment because it sets the stage for describing the sorts of data and information available through the Internet. It helps you diagnose where problems may be occurring when your Internet searching experiences prove fruitless. It helps you understand that the Internet can only provide you with data, and at most, information, but not knowledge and wisdom.
From a computing standpoint, flexible user interface development is the most obvious advantage of the client/server model. It is possible to create an interface independent of the server hosting data. Therefore, the user interface of a client/server application can be written on a Macintosh and the server can be written on a mainframe.
Client/server computing also allows information to be stored in a central server and disseminated to different types of remote computers. Since the user interface is the responsibility of the client, the server has more computing resources to spend on analyzing queries and disseminating information. This is another major advantage of client/server computing; it tends to use the strengths of divergent computing platforms to create more powerful applications. Although its computing and storage capabilities are dwarfed by those of the mainframe, there is no reason why a Macintosh could not be used as a server for less demanding applications.